RESUMEN
1 INTRODUCCIÓN
- Conjuntos de datos enormes con altas tasas de ingestión. Muchas aplicaciones basadas en datos de sectores como la analítica web, las finanzas y el comercio electrónico se caracterizan por volúmenes de datos enormes y en continuo crecimiento. Para manejar conjuntos de datos de gran tamaño, las bases de datos analíticas no solo deben ofrecer estrategias eficientes de indexación y compresión, sino también permitir la distribución de datos entre varios nodos (escalado horizontal), ya que los servidores individuales están limitados a varias decenas de terabytes de almacenamiento. Además, los datos recientes suelen ser más relevantes para obtener información en tiempo real que los datos históricos. Como resultado, las bases de datos analíticas deben ser capaces de ingestar datos nuevos a tasas altas y sostenidas o por ráfagas, así como de “despriorizar” continuamente (por ejemplo, agregando o archivando) los datos históricos sin ralentizar las consultas de informes que se ejecutan en paralelo.
- Muchas consultas simultáneas con expectativas de baja latencia. Por lo general, las consultas pueden clasificarse como ad hoc (por ejemplo, análisis exploratorio de datos) o recurrentes (por ejemplo, consultas periódicas de dashboard). Cuanto más interactivo sea un caso de uso, menor será la latencia esperada de las consultas, lo que plantea desafíos para la optimización y la ejecución de consultas. Las consultas recurrentes también brindan la oportunidad de adaptar la disposición física de la base de datos a la carga de trabajo. Como resultado, las bases de datos deben ofrecer técnicas de poda que permitan optimizar las consultas frecuentes. Según la prioridad de la consulta, las bases de datos también deben otorgar acceso equitativo o priorizado a recursos compartidos del sistema, como CPU, memoria, disco y E/S de red, incluso si se ejecuta simultáneamente un gran número de consultas.
- Entornos diversos de almacenes de datos, ubicaciones de almacenamiento y formatos. Para integrarse con las arquitecturas de datos existentes, las bases de datos analíticas modernas deben mostrar un alto grado de apertura para leer y escribir datos externos en cualquier sistema, ubicación o formato.
- Un lenguaje de consulta práctico con soporte para la introspección del rendimiento. El uso de bases de datos OLAP en el mundo real plantea requisitos “blandos” adicionales. Por ejemplo, en lugar de un lenguaje de programación de nicho, los usuarios suelen preferir interactuar con las bases de datos mediante un dialecto SQL expresivo con tipos de datos anidados y una amplia variedad de funciones regulares, de agregación y de ventana. Las bases de datos analíticas también deben proporcionar herramientas sofisticadas para inspeccionar el rendimiento del sistema o de consultas individuales.
- Robustez de nivel industrial y despliegue versátil. Dado que el hardware convencional no es fiable, las bases de datos deben proporcionar replicación de datos para ofrecer solidez frente a fallos de nodos. Además, las bases de datos deben ejecutarse en cualquier hardware, desde portátiles antiguos hasta servidores potentes. Por último, para evitar la sobrecarga de la recolección de basura en programas basados en la JVM y obtener rendimiento bare-metal (por ejemplo, SIMD), lo ideal es que las bases de datos se desplieguen como binarios nativos para la plataforma de destino.

2 ARQUITECTURA
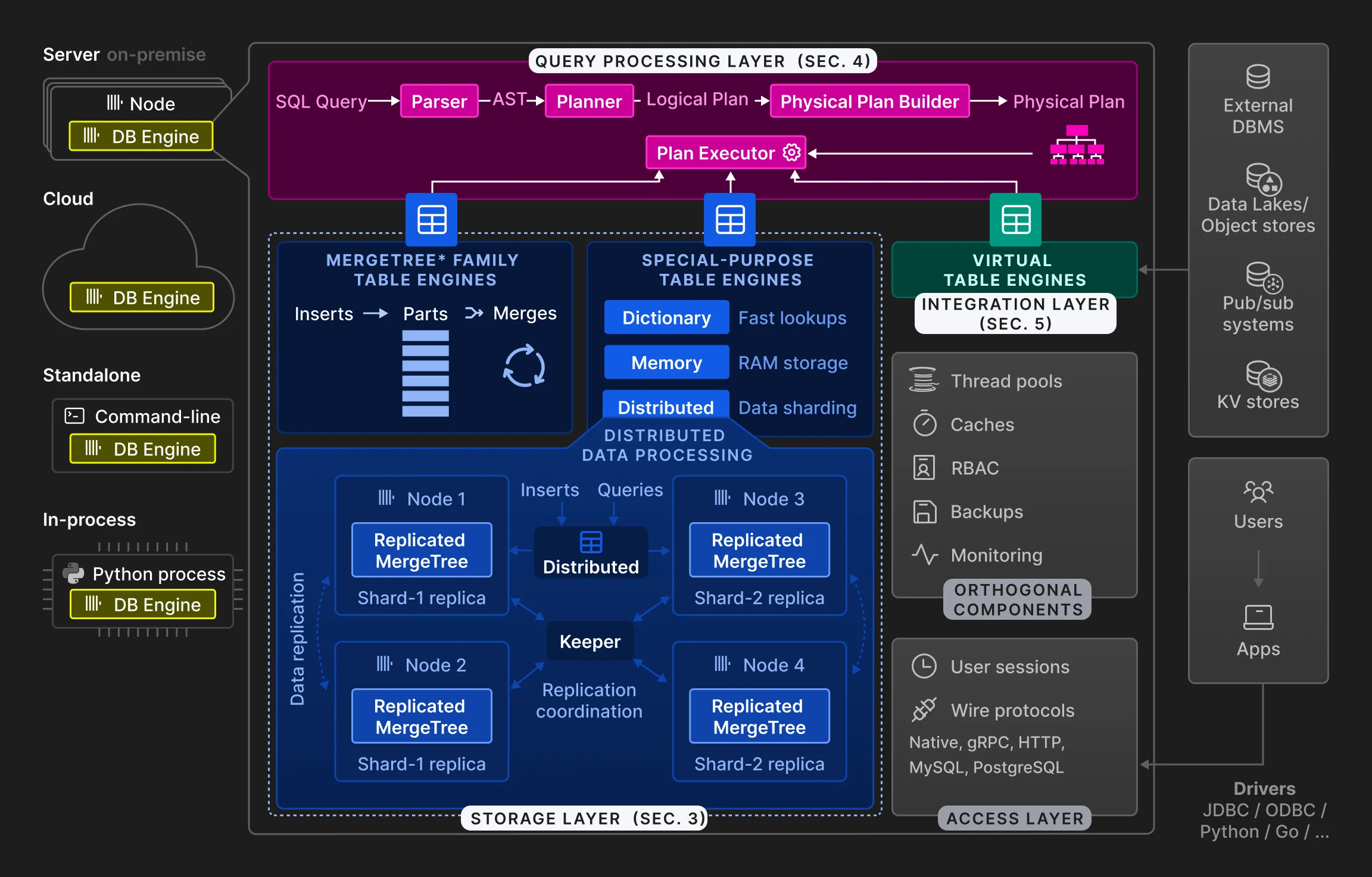
3 CAPA DE ALMACENAMIENTO
En esta sección se analizan los motores de tablas MergeTree* como formato de almacenamiento nativo de ClickHouse. Describimos su representación en disco y analizamos tres técnicas de poda de datos en ClickHouse. A continuación, presentamos estrategias de merge que transforman continuamente los datos sin afectar a las inserciones simultáneas. Por último, explicamos cómo se implementan las actualizaciones y eliminaciones, así como la deduplicación de datos, la replicación de datos y la conformidad con ACID.3.1 Formato en disco
Cada tabla del motor de tablas MergeTree* está organizada como una colección de partes de tabla inmutables. Se crea una parte cada vez que se inserta un conjunto de filas en la tabla. Las partes son autocontenidas, en el sentido de que incluyen todos los metadatos necesarios para interpretar su contenido sin consultas adicionales a un catálogo central. Para mantener bajo el número de partes por tabla, un proceso de merge en segundo plano combina periódicamente varias partes más pequeñas en una parte más grande hasta alcanzar un tamaño de parte configurable (150 GB de forma predeterminada). Dado que las partes se ordenan por las columnas de clave primaria de la tabla (consulte la Sección 3.2), para el merging se utiliza una ordenación por mezcla de k vías eficiente [40]. Las partes de origen se marcan como inactivas y finalmente se eliminan en cuanto su recuento de referencias se reduce a cero, es decir, cuando ya no hay consultas que lean de ellas. Las filas pueden insertarse de dos maneras: en el modo de insert síncrono, cada sentencia INSERT crea una nueva parte y la agrega a la tabla. Para minimizar la sobrecarga de los merges, se recomienda a los clientes de base de datos insertar Tuples en bloque, por ejemplo, 20.000 filas de una sola vez. Sin embargo, los retrasos provocados por el batching del lado del cliente suelen ser inaceptables si los datos deben analizarse en tiempo real. Por ejemplo, los casos de uso de observabilidad suelen implicar miles de agentes de monitorización que envían continuamente pequeñas cantidades de datos de eventos y métricas. Estos escenarios pueden utilizar el modo de insert asíncrono, en el que ClickHouse almacena en un búfer filas de múltiples operaciones INSERT entrantes en la misma tabla y crea una nueva parte solo cuando el tamaño del búfer supera un umbral configurable o expira un timeout.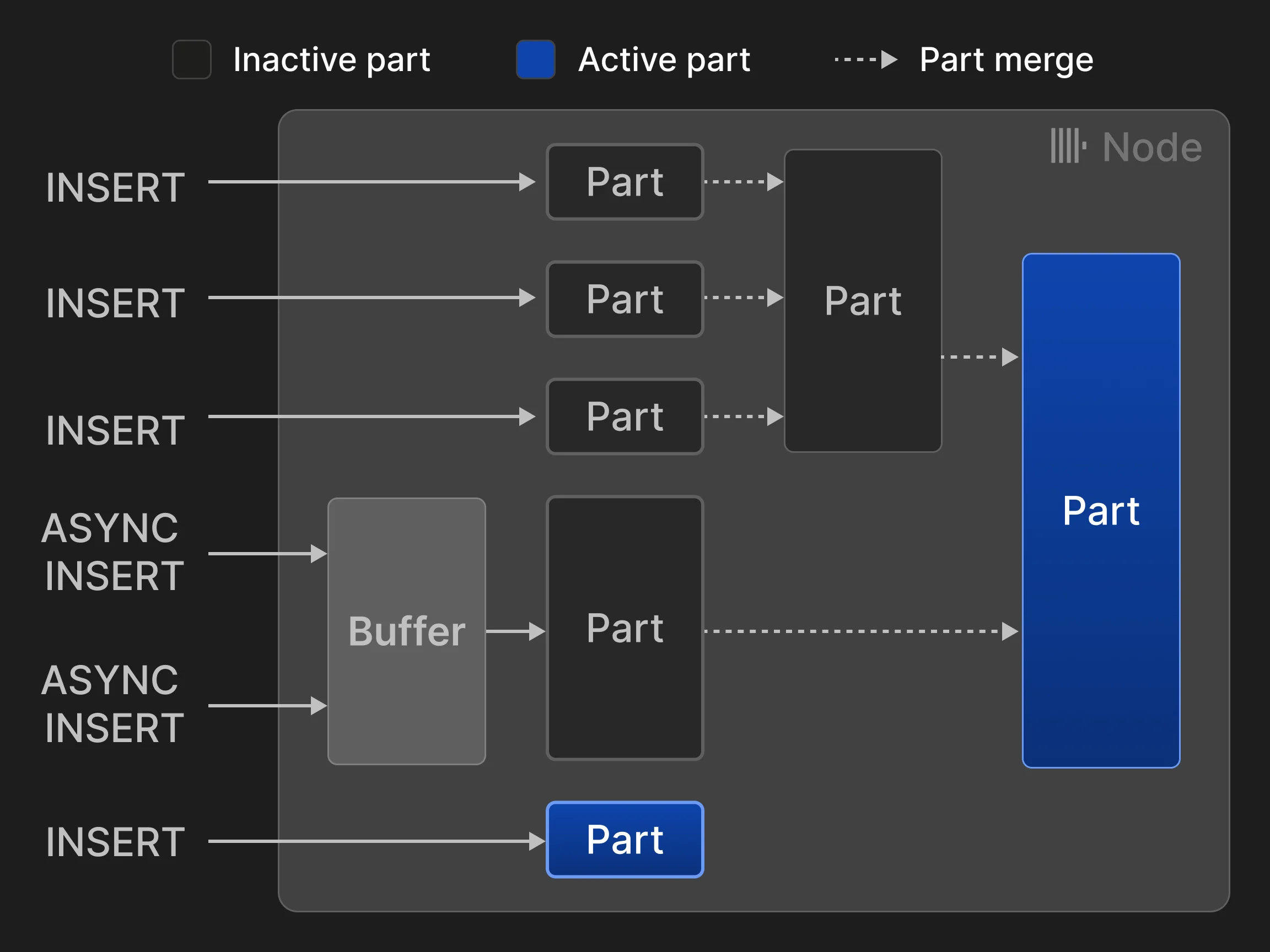
3.2 Poda de datos
En la mayoría de los casos de uso, escanear petabytes de datos solo para responder una consulta es demasiado lento y costoso. ClickHouse admite tres técnicas de poda de datos que permiten omitir la mayoría de las filas durante las búsquedas y, por tanto, acelerar significativamente las consultas. En primer lugar, los usuarios pueden definir un índice de clave primaria para una tabla. Las columnas de la clave primaria determinan el orden de las filas dentro de cada parte; es decir, el índice está agrupado localmente. Además, ClickHouse almacena, para cada parte, un mapeo entre los valores de las columnas de la clave primaria de la primera fila de cada gránulo y el id del gránulo; es decir, el índice es disperso [31]. La estructura de datos resultante suele ser lo bastante pequeña como para mantenerse completamente en memoria; por ejemplo, solo se necesitan 1000 entradas para indexar 8,1 millones de filas. El objetivo principal de una clave primaria es evaluar predicados de igualdad y de rango en columnas que se filtran con frecuencia mediante búsqueda binaria en lugar de exploraciones secuenciales (Sección 4.4). La ordenación local también puede aprovecharse para las fusiones de partes y la optimización de consultas; por ejemplo, para la agregación basada en ordenación o para eliminar operadores de ordenación del plan de ejecución físico cuando las columnas de la clave primaria forman un prefijo de las columnas de ordenación. La Figura 4 muestra un índice de clave primaria en la columna EventTime para una tabla con estadísticas de impresiones de página. Los gránulos que coinciden con el predicado de rango de la consulta pueden encontrarse mediante búsqueda binaria en el índice de clave primaria, en lugar de escanear EventTime secuencialmente.
3.3 Transformación de datos durante la fusión
Los casos de uso de inteligencia empresarial y observabilidad a menudo necesitan manejar datos generados a tasas constantemente altas o en ráfagas. Además, los datos generados recientemente suelen ser más relevantes para obtener información significativa en tiempo real que los datos históricos. Estos casos de uso requieren bases de datos capaces de sostener altas tasas de ingestión de datos mientras reducen continuamente el volumen de datos históricos mediante técnicas como la agregación o el envejecimiento de datos. ClickHouse permite la transformación incremental continua de los datos existentes mediante distintas estrategias de fusión. La transformación de datos durante la fusión no compromete el rendimiento de las sentencias INSERT, pero no puede garantizar que las tablas nunca contengan valores no deseados (p. ej., obsoletos o no agregados). Si es necesario, todas las transformaciones durante la fusión pueden aplicarse en tiempo de consulta especificando la palabra clave FINAL en sentencias SELECT. Las fusiones de reemplazo conservan solo la versión más reciente de una tupla insertada, según la marca de tiempo de creación de la parte que la contiene; las versiones anteriores se eliminan. Las tuplas se consideran equivalentes si tienen los mismos valores en las columnas de clave primaria. Para controlar explícitamente qué tupla se conserva, también es posible especificar una columna de versión especial para la comparación. Las fusiones de reemplazo se usan habitualmente como mecanismo de actualización durante la fusión (normalmente en casos de uso donde las actualizaciones son frecuentes), o como alternativa a la deduplicación de datos en tiempo de inserción (Sección 3.5). Las fusiones de agregación colapsan filas con valores iguales en las columnas de clave primaria en una fila agregada. Las columnas que no son de clave primaria deben ser de tipo estado de agregación parcial, que contiene los valores de resumen. Dos estados de agregación parcial, p. ej., una suma y un conteo para avg(), se combinan en un nuevo estado de agregación parcial. Las fusiones de agregación suelen usarse en vistas materializadas en lugar de tablas normales. Las vistas materializadas se rellenan a partir de una consulta de transformación sobre una tabla de origen. A diferencia de otras bases de datos, ClickHouse no actualiza periódicamente las vistas materializadas con el contenido completo de la tabla de origen. En su lugar, las vistas materializadas se actualizan de forma incremental con el resultado de la consulta de transformación cuando se inserta una nueva parte en la tabla de origen. La Figura 5 muestra una vista materializada definida sobre una tabla con estadísticas de impresiones de página. Para las nuevas partes insertadas en la tabla de origen, la consulta de transformación calcula las latencias máxima y media, agrupadas por región, e inserta el resultado en una vista materializada. Las funciones de agregación avg() y max() con la extensión -State devuelven estados de agregación parcial en lugar de resultados finales. Una fusión de agregación definida para la vista materializada combina continuamente estados de agregación parcial en diferentes partes. Para obtener el resultado final, los usuarios consolidan los estados de agregación parcial en la vista materializada usando avg() y max()) con la extensión -Merge.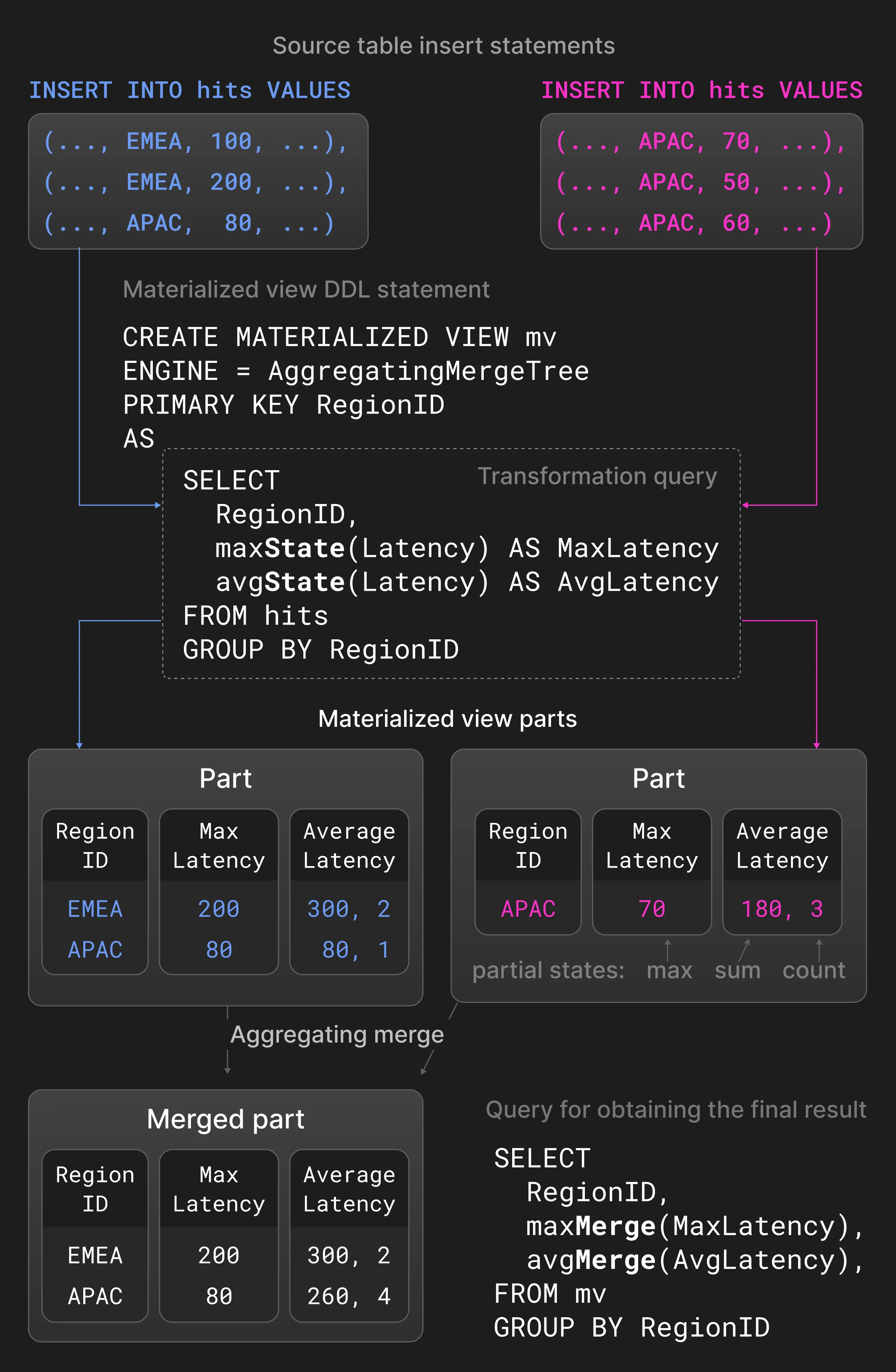
3.4 Actualizaciones y eliminaciones
El diseño de los motores de tabla MergeTree* favorece las cargas de trabajo de solo inserción, aunque algunos casos de uso requieren modificar datos existentes de forma ocasional, por ejemplo, para el cumplimiento normativo. Existen dos enfoques para actualizar o eliminar datos, y ninguno de ellos bloquea las inserciones paralelas. Mutaciones reescriben todas las partes de una tabla in-place. Para evitar que una tabla (delete) o una columna (update) duplique temporalmente su tamaño, esta operación no es atómica; es decir, las sentencias SELECT paralelas pueden leer partes mutadas y no mutadas. Las mutaciones garantizan que los datos queden modificados físicamente al final de la operación. Las mutaciones de eliminación siguen siendo costosas, ya que reescriben todas las columnas en todas las partes. Como alternativa, las eliminaciones ligeras solo actualizan una columna bitmap interna, indicando si una fila está eliminada o no. ClickHouse modifica las consultas SELECT con un filtro adicional sobre la columna bitmap para excluir las filas eliminadas del resultado. Las filas eliminadas se quitan físicamente solo mediante fusiones regulares en algún momento no especificado del futuro. Según la cantidad de columnas, las eliminaciones ligeras pueden ser mucho más rápidas que las mutaciones, a costa de consultas SELECT más lentas. Se espera que las operaciones de actualización y eliminación realizadas sobre la misma tabla sean poco frecuentes y se serialicen para evitar conflictos lógicos.3.5 Inserciones idempotentes
Un problema que se presenta con frecuencia en la práctica es cómo deben manejar los clientes los tiempos de espera de conexión después de enviar datos al servidor para insertarlos en una tabla. En esta situación, a los clientes les resulta difícil determinar si los datos se insertaron correctamente o no. Tradicionalmente, el problema se resuelve reenviando los datos del cliente al servidor y confiando en la clave primaria o en las restricciones de unicidad para rechazar inserciones duplicadas. Las bases de datos realizan rápidamente las búsquedas puntuales necesarias mediante estructuras de índice basadas en árboles binarios [39, [68]](#page-13-16), árboles radix [45] o tablas hash [29]. Dado que estas estructuras de datos indexan cada tupla, su sobrecarga de espacio y actualización se vuelve prohibitiva para conjuntos de datos grandes y altas tasas de ingesta. ClickHouse proporciona una alternativa más ligera basada en el hecho de que cada inserción acaba creando una parte. Más concretamente, el servidor mantiene hashes de las N últimas partes insertadas (p. ej., N=100) e ignora las reinserciones de partes con un hash conocido. Los hashes de las tablas no replicadas y replicadas se almacenan localmente y en Keeper, respectivamente. Como resultado, las inserciones se vuelven idempotentes; es decir, los clientes pueden simplemente reenviar el mismo lote de filas después de un timeout y asumir que el servidor se encarga de la deduplicación. Para tener un mayor control sobre el proceso de deduplicación, los clientes pueden proporcionar opcionalmente un token de inserción que actúe como hash de la parte. Aunque la deduplicación basada en hashes implica una sobrecarga asociada al cálculo del hash de las filas nuevas, el coste de almacenar y comparar hashes es insignificante.3.6 Replicación de datos
La replicación es un requisito previo para la alta disponibilidad (tolerancia frente a fallos de nodos), pero también se utiliza para el balanceo de carga y las actualizaciones sin tiempo de inactividad [14]. En ClickHouse, la replicación se basa en la noción de estados de tabla, que consisten en un conjunto de partes de la tabla (Sección 3.1) y metadatos de la tabla, como nombres de columnas y tipos. Los nodos hacen avanzar el estado de una tabla mediante tres operaciones: 1. las inserciones añaden una nueva parte al estado, 2. las fusiones añaden una nueva parte al estado y eliminan de él partes existentes, 3. las mutaciones y las sentencias DDL añaden partes, y/o eliminan partes, y/o modifican los metadatos de la tabla, según la operación concreta. Las operaciones se realizan localmente en un único nodo y se registran como una secuencia de transiciones de estado en un registro global de replicación. El registro de replicación lo mantiene un conjunto de, por lo general, tres procesos de ClickHouse Keeper que utilizan el algoritmo de consenso Raft [59] para proporcionar una capa de coordinación distribuida y tolerante a fallos para un clúster de nodos de ClickHouse. Inicialmente, todos los nodos del clúster apuntan a la misma posición en el registro de replicación. Mientras los nodos ejecutan localmente inserciones, fusiones, mutaciones y sentencias DDL, el registro de replicación se reproduce de forma asíncrona en todos los demás nodos. Como resultado, las tablas replicadas solo ofrecen consistencia eventual; es decir, los nodos pueden leer temporalmente estados antiguos de la tabla mientras convergen hacia el estado más reciente. La mayoría de las operaciones antes mencionadas también pueden ejecutarse de forma síncrona hasta que un cuórum de nodos (por ejemplo, una mayoría de nodos o todos los nodos) haya adoptado el nuevo estado. Como ejemplo, la Figura 6 muestra una tabla replicada inicialmente vacía en un clúster de tres nodos de ClickHouse. El nodo 1 recibe primero dos sentencias INSERT y las registra ( 1 2 ) en el registro de replicación almacenado en el conjunto de Keeper. A continuación, el nodo 2 reproduce la primera entrada del registro recuperándola ( 3 ) y descargando la nueva parte desde el nodo 1 ( 4 ), mientras que el nodo 3 reproduce ambas entradas del registro ( 3 4 5 6 ). Por último, el nodo 3 fusiona ambas partes en una nueva parte, elimina las partes de entrada y registra una entrada de fusión en el registro de replicación ( 7 ).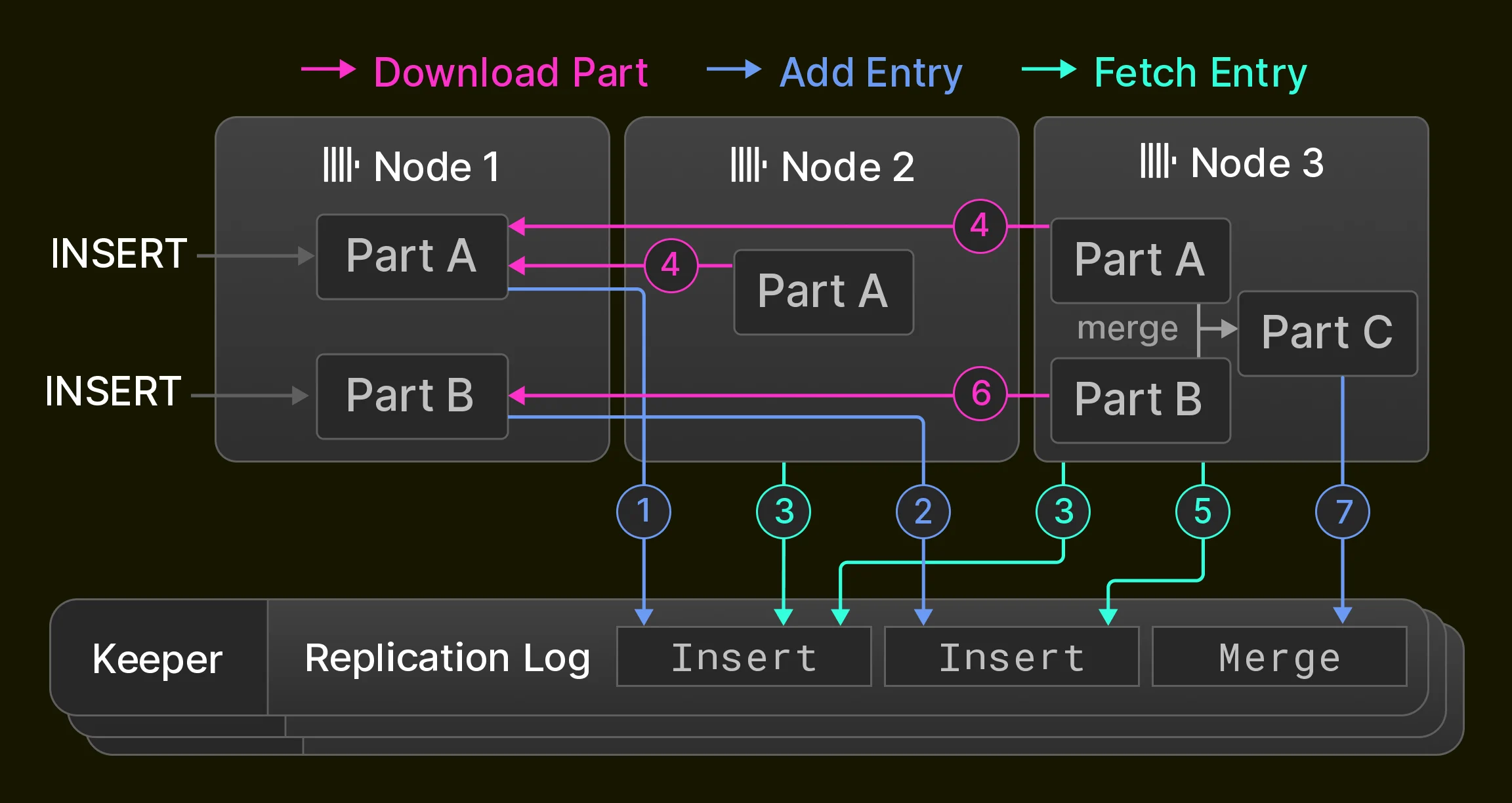
3.7 Cumplimiento de ACID
Para maximizar el rendimiento de las operaciones concurrentes de lectura y escritura, ClickHouse evita en la medida de lo posible los bloqueos. Las consultas se ejecutan sobre una instantánea de todas las partes de todas las tablas implicadas, creada al inicio de la consulta. Esto garantiza que las partes nuevas insertadas por INSERTs o fusiones paralelos (Sección 3.1) no participen en la ejecución. Para evitar que las partes se modifiquen o eliminen simultáneamente (Sección 3.4), el recuento de referencias de las partes procesadas se incrementa durante toda la consulta. Formalmente, esto corresponde al aislamiento de instantánea implementado mediante una variante de MVCC [6] basada en partes versionadas. Como resultado, las sentencias, por lo general, no cumplen con ACID, salvo en el caso poco frecuente de que las escrituras concurrentes, en el momento en que se toma la instantánea, afecten cada una a una sola parte. En la práctica, la mayoría de los casos de uso de ClickHouse orientados a la toma de decisiones y con una alta carga de escrituras toleran incluso un pequeño riesgo de perder datos nuevos en caso de un corte de energía. La base de datos aprovecha esto y, de forma predeterminada, no fuerza un commit (fsync) de las partes recién insertadas en disco, lo que permite al kernel agrupar las escrituras a costa de renunciar a la atomicidad.4 CAPA DE PROCESAMIENTO DE CONSULTAS
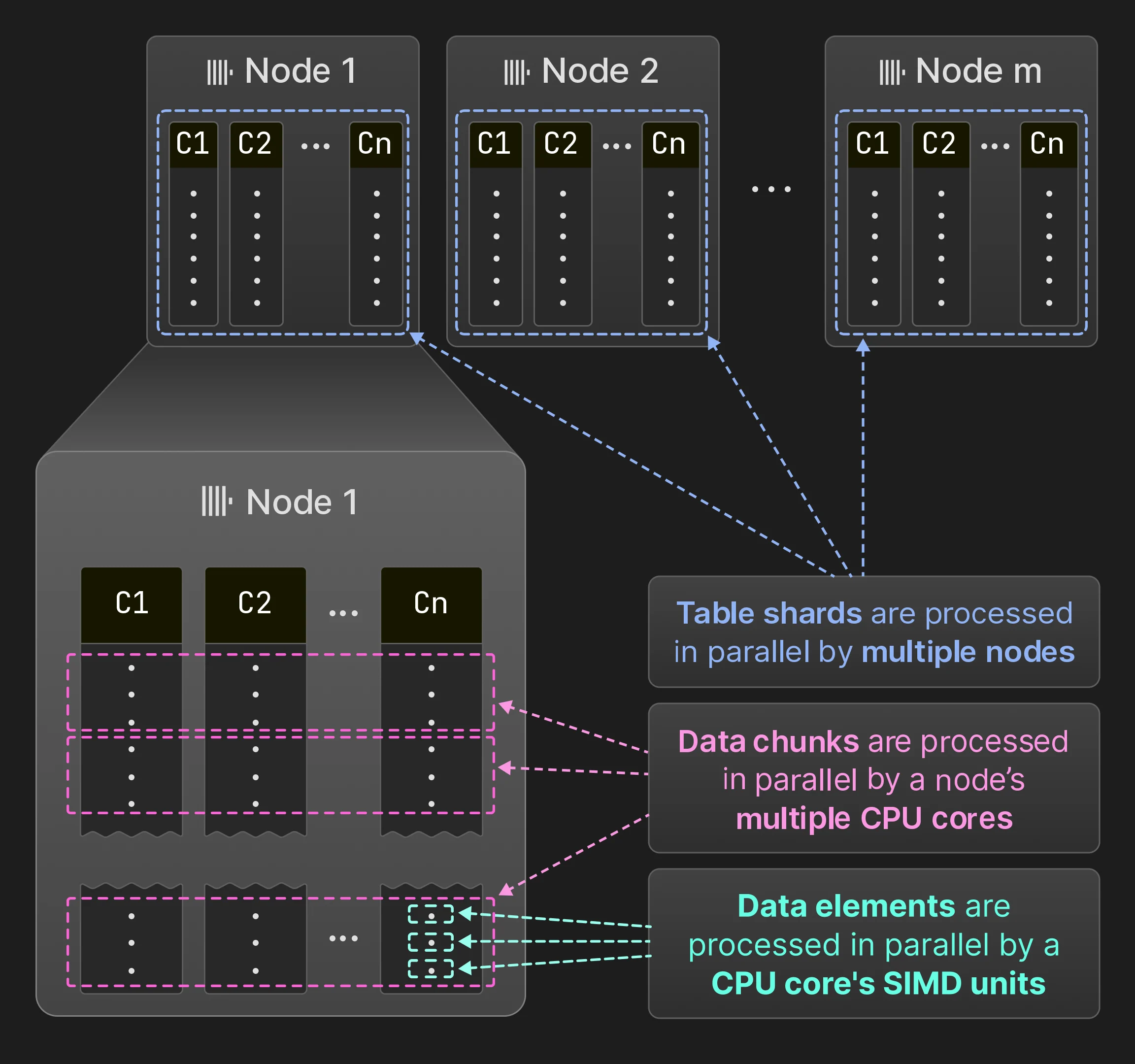
4.1 Paralelización SIMD
4.2 Paralelización multinúcleo
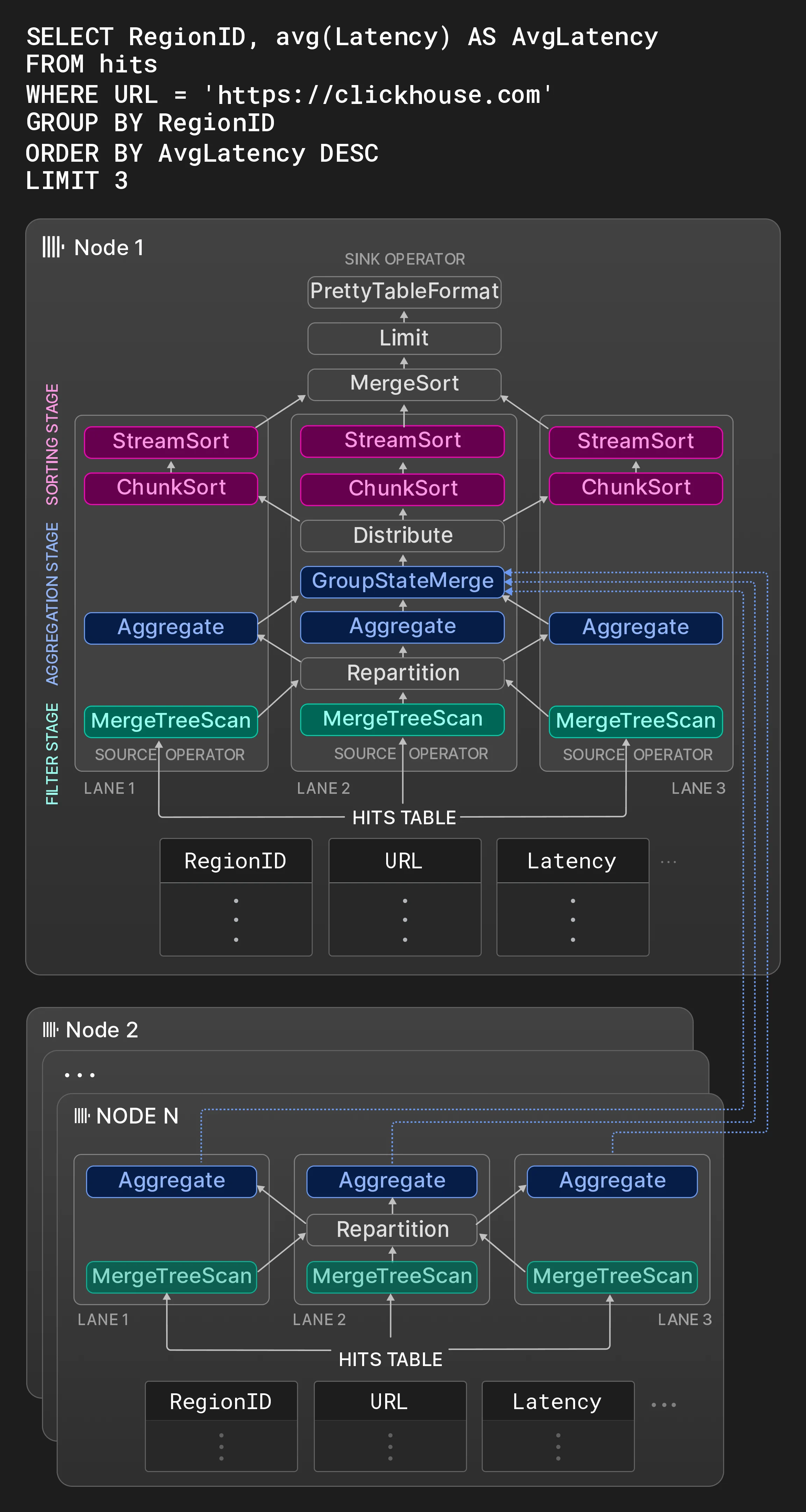
4.3 Paralelización multinodo
4.4 Optimización integral del rendimiento
Esta sección presenta optimizaciones clave del rendimiento aplicadas a distintas etapas de la ejecución de consultas. Optimización de consultas. El primer conjunto de optimizaciones se aplica sobre una representación semántica de la consulta obtenida a partir de su AST. Algunos ejemplos de estas optimizaciones incluyen el plegado de constantes (p. ej., concat(lower(‘a’),upper(‘b’)) se convierte en ‘aB’), la extracción de escalares de determinadas funciones de agregación (p. ej., sum(a2) se convierte en 2 * sum(a)), la eliminación de subexpresiones comunes y la transformación de disyunciones de filtros de igualdad en listas IN (p. ej., x=c OR x=d se convierte en x IN (c,d)). Posteriormente, la representación semántica optimizada de la consulta se transforma en un plan lógico de operadores. Las optimizaciones sobre el plan lógico incluyen el pushdown de filtros y la reordenación de la evaluación de funciones y de los pasos de ordenación, según cuál de ellos se estime más costoso. Por último, el plan lógico de la consulta se transforma en un plan físico de operadores. Esta transformación puede aprovechar las particularidades de los motores de tabla involucrados. Por ejemplo, en el caso de un motor de tabla MergeTree, si las columnas de ORDER BY forman un prefijo de la clave primaria, los datos pueden leerse en el orden en disco y los operadores de ordenación pueden eliminarse del plan. Además, si las columnas de agrupación de una agregación forman un prefijo de la clave primaria, ClickHouse puede usar agregación por ordenación [33], es decir, agregar directamente secuencias del mismo valor en entradas ya ordenadas. En comparación con la agregación por hash, la agregación por ordenación consume mucha menos memoria, y el valor agregado puede pasarse al siguiente operador inmediatamente después de procesar una secuencia. Compilación de consultas. ClickHouse emplea compilación de consultas basada en LLVM para fusionar dinámicamente operadores de plan adyacentes [38, [53]](#page-13-0). Por ejemplo, la expresión a * b + c + 1 puede combinarse en un único operador en lugar de tres operadores. Además de las expresiones, ClickHouse también emplea compilación para evaluar varias funciones de agregación a la vez (es decir, para GROUP BY) y para ordenar con más de una clave de ordenación. La compilación de consultas reduce el número de llamadas virtuales, mantiene los datos en registros o en la caché de la CPU y ayuda al predictor de saltos, ya que es necesario ejecutar menos código. Además, la compilación en tiempo de ejecución permite un amplio conjunto de optimizaciones, como optimizaciones lógicas y optimizaciones peephole implementadas en compiladores, y da acceso a las instrucciones de CPU disponibles localmente más rápidas. La compilación se inicia solo cuando la misma expresión normal, de agregación o de ordenación es ejecutada por distintas consultas más de un número configurable de veces. Los operadores de consulta compilados se almacenan en caché y pueden reutilizarse en consultas futuras.[7] Evaluación del índice de clave primaria. ClickHouse evalúa las condiciones WHERE usando el índice de clave primaria si un subconjunto de cláusulas de filtro en la forma normal conjuntiva de la condición constituye un prefijo de las columnas de la clave primaria. El índice de clave primaria se analiza de izquierda a derecha sobre rangos de valores de clave ordenados lexicográficamente. Las cláusulas de filtro correspondientes a una columna de clave primaria se evalúan mediante lógica ternaria: todas verdaderas, todas falsas o una mezcla de verdaderas y falsas para los valores del rango. En este último caso, el rango se divide en subrangos que se analizan recursivamente. Existen optimizaciones adicionales para funciones en las condiciones de filtro. En primer lugar, las funciones tienen rasgos que describen su monotonía; por ejemplo, toDayOfMonth(date) es monótona por tramos dentro de un mes. Los rasgos de monotonía permiten inferir si una función produce resultados ordenados sobre rangos ordenados de valores clave de entrada. En segundo lugar, algunas funciones pueden calcular la preimagen de un resultado de función dado. Esto se usa para sustituir comparaciones de constantes con llamadas a funciones sobre las columnas clave por comparaciones entre el valor de la columna clave y la preimagen. Por ejemplo, toYear(k) = 2024 puede reemplazarse por k >= 2024-01-01 && k < 2025-01-01. Salto de datos. ClickHouse intenta evitar lecturas de datos en tiempo de ejecución de la consulta usando las estructuras de datos presentadas en la Sección 3.2. Además, los filtros sobre distintas columnas se evalúan secuencialmente en orden descendente de selectividad estimada, basándose en heurísticas y estadísticas de columna (opcionales). Solo los fragmentos de datos que contienen al menos una fila coincidente se pasan al siguiente predicado. Esto reduce gradualmente la cantidad de datos leídos y el número de cálculos que deben realizarse de un predicado a otro. La optimización solo se aplica cuando hay al menos un predicado altamente selectivo; de lo contrario, la latencia de la consulta empeoraría en comparación con una evaluación de todos los predicados en paralelo. Tablas hash. Las tablas hash son estructuras de datos fundamentales para la agregación y los hash join. Elegir el tipo adecuado de tabla hash es crucial para el rendimiento. ClickHouse instancia varias tablas hash (más de 30 en marzo de 2024) a partir de una plantilla genérica de tabla hash, con la función hash, el asignador, el tipo de celda y la política de redimensionamiento como puntos de variación. En función del tipo de dato de las columnas de agrupación, la cardinalidad estimada de la tabla hash y otros factores, se selecciona de forma individual la tabla hash más rápida para cada operador de consulta. Otras optimizaciones implementadas para las tablas hash incluyen:- un diseño de dos niveles con 256 subtablas (basadas en el primer byte del hash) para admitir conjuntos de claves muy grandes,
- tablas hash de cadenas [79] con cuatro subtablas y distintas funciones hash para diferentes longitudes de cadena,
- tablas de búsqueda que usan la clave directamente como índice del bucket (es decir, sin aplicar hashing) cuando solo hay unas pocas claves,
- valores con hashes integrados para resolver colisiones más rápido cuando la comparación es costosa (p. ej., cadenas, AST),
- creación de tablas hash basada en tamaños previstos a partir de estadísticas de tiempo de ejecución para evitar redimensionamientos innecesarios,
- asignación de varias tablas hash pequeñas con el mismo ciclo de vida de creación/destrucción en un único slab de memoria,
- vaciado instantáneo de tablas hash para reutilizarlas mediante contadores de versión por mapa hash y por celda,
- uso de prefetch de CPU (__builtin_prefetch) para acelerar la recuperación de valores después de aplicar hash a la clave.
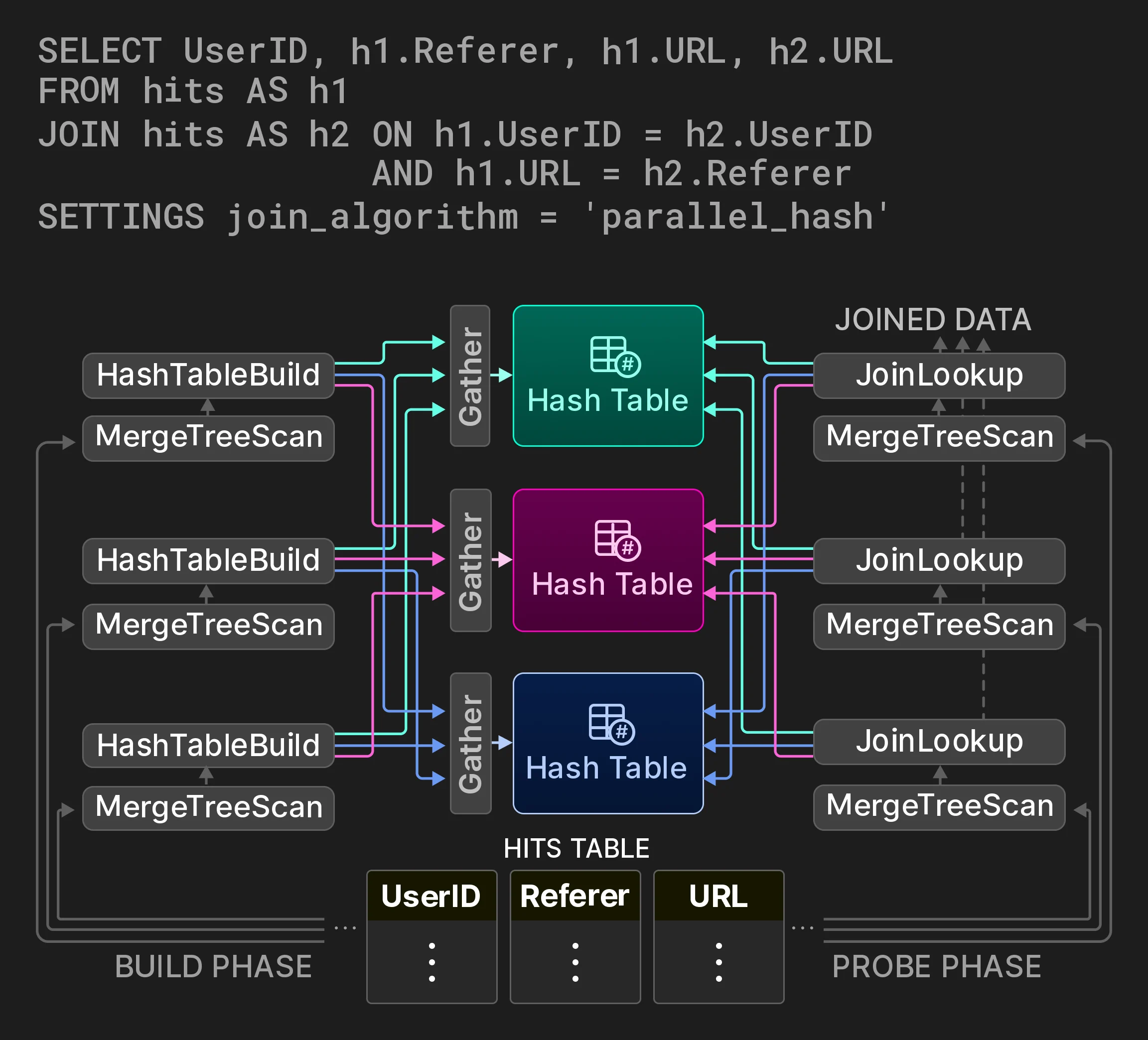
4.5 Aislamiento de cargas de trabajo
ClickHouse ofrece control de concurrencia, límites de uso de memoria y planificación de E/S, lo que permite a los usuarios aislar las consultas en clases de carga de trabajo. Al establecer límites sobre recursos compartidos (núcleos de CPU, DRAM y E/S de disco y red) para clases de carga de trabajo específicas, garantiza que estas consultas no afecten a otras consultas críticas para el negocio. El control de concurrencia evita la sobresuscripción de hilos en escenarios con un gran número de consultas concurrentes. Más concretamente, el número de hilos de trabajo por consulta se ajusta dinámicamente en función de una proporción especificada respecto al número de núcleos de CPU disponibles. ClickHouse supervisa el tamaño en bytes de las asignaciones de memoria a nivel de servidor, usuario y consulta, y de este modo permite establecer límites flexibles de uso de memoria. La sobreasignación de memoria permite que las consultas usen memoria libre adicional más allá de la memoria garantizada, a la vez que garantiza límites de memoria para otras consultas. Además, el uso de memoria para las cláusulas de agregación, ordenación y join puede limitarse, lo que hace que se recurra a algoritmos externos cuando se supera el límite de memoria. Por último, la planificación de E/S permite a los usuarios restringir los accesos a disco locales y remotos para las clases de carga de trabajo en función de un ancho de banda máximo, solicitudes en curso y una política (p. ej. FIFO, SFC [32]).5 CAPA DE INTEGRACIÓN
Las aplicaciones de toma de decisiones en tiempo real suelen depender de un acceso eficiente y de baja latencia a datos distribuidos en múltiples ubicaciones. Existen dos enfoques para poner datos externos a disposición en una base de datos OLAP. Con el acceso a datos basado en push, un componente de terceros conecta la base de datos con almacenes de datos externos. Un ejemplo de ello son las herramientas especializadas de extracción, transformación y carga (ETL), que envían datos remotos al sistema de destino. En el modelo basado en pull, la propia base de datos se conecta a fuentes de datos remotas y extrae datos para consultarlos en tablas locales o exporta datos a sistemas remotos. Aunque los enfoques basados en push son más versátiles y habituales, conllevan una mayor complejidad arquitectónica y un cuello de botella en la escalabilidad. En cambio, la conectividad remota directamente en la base de datos ofrece capacidades interesantes, como joins entre datos locales y remotos, a la vez que mantiene una arquitectura más simple y reduce el tiempo necesario para obtener información útil. El resto de la sección explora métodos de integración de datos basados en pull en ClickHouse, orientados al acceso a datos en ubicaciones remotas. Cabe señalar que la idea de la conectividad remota en bases de datos SQL no es nueva. Por ejemplo, el estándar SQL/MED [35], introducido en 2001 e implementado por PostgreSQL desde 2011 [65], propone los foreign data wrappers como una interfaz unificada para gestionar datos externos. La máxima interoperabilidad con otros almacenes de datos y formatos de almacenamiento es uno de los objetivos de diseño de ClickHouse. A marzo de 2024, ClickHouse ofrece, hasta donde sabemos, la mayor cantidad de opciones de integración de datos integradas entre todas las bases de datos analíticas. Conectividad externa. ClickHouse proporciona más de 50 funciones de tabla y motores de integración para conectividad con sistemas externos y ubicaciones de almacenamiento, incluidos ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, almacenes de objetos S3/GCP/Azure y varios lagos de datos. Las desglosamos además en categorías, como se muestra en la siguiente figura adicional (no forma parte del artículo original de VLDB).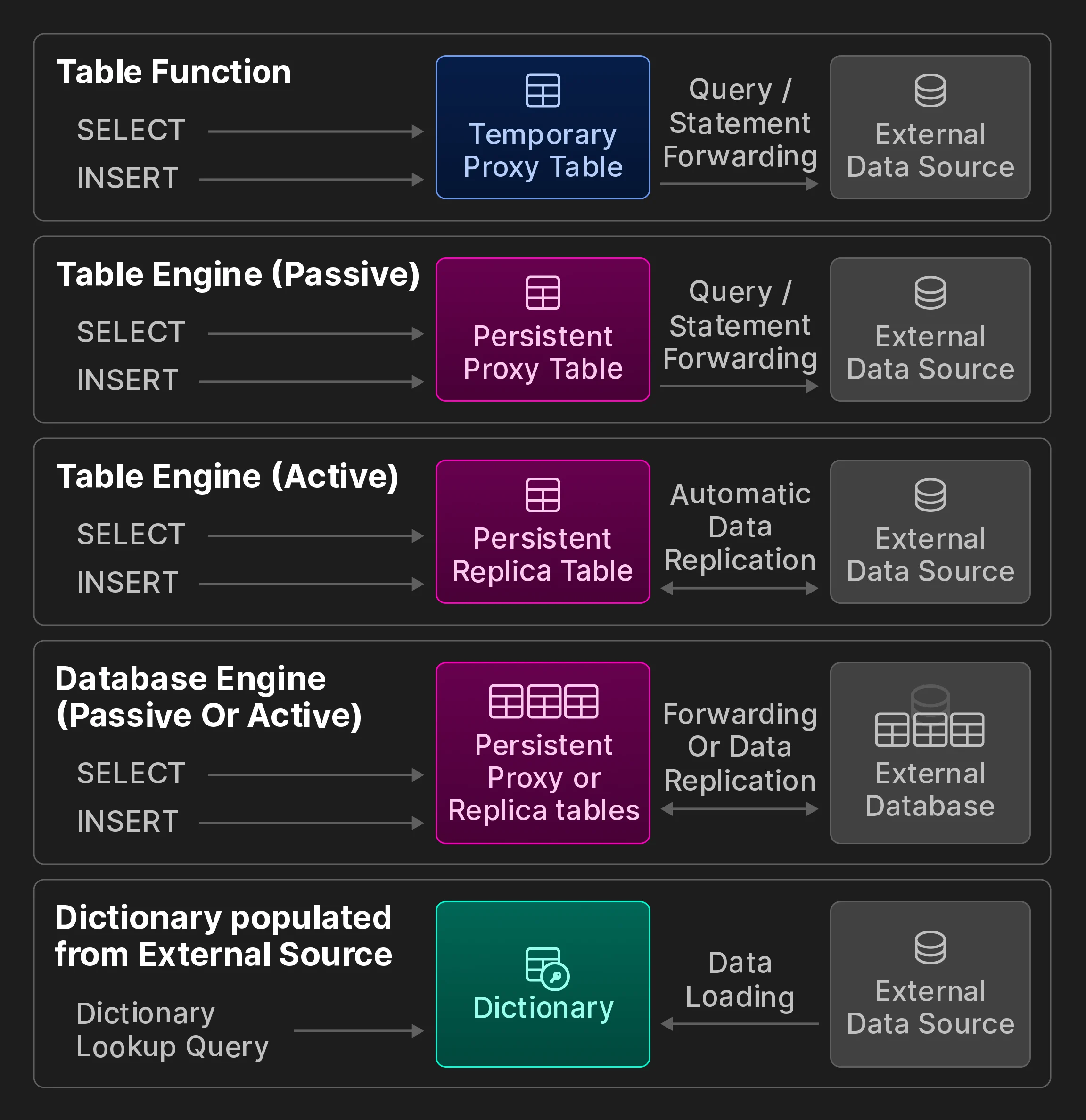
6 EL RENDIMIENTO COMO FUNCIONALIDAD
6.1 Herramientas integradas de análisis de rendimiento
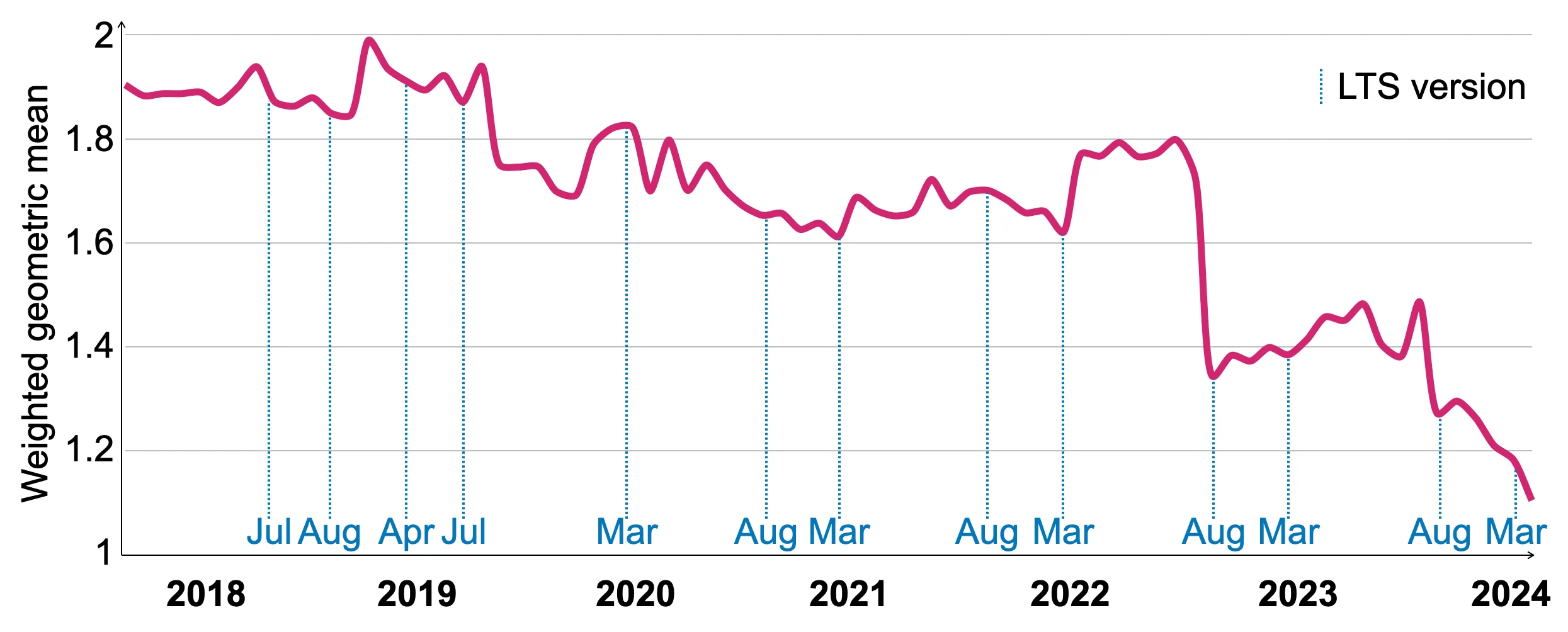
6.2 Benchmarks
6.2.1 Tablas desnormalizadas
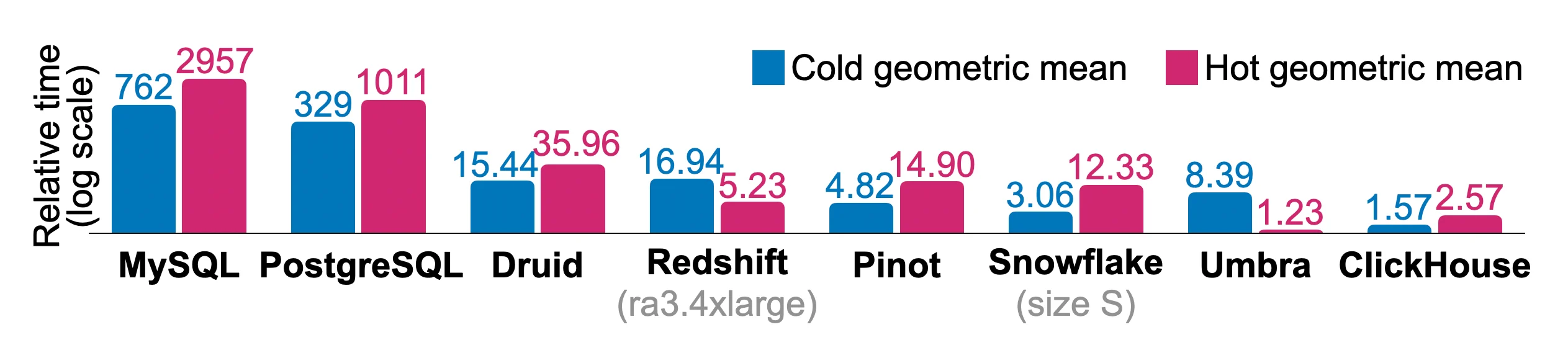
6.2.2 Tablas normalizadas

8 CONCLUSIÓN Y PERSPECTIVAS
AGRADECIMIENTOS
REFERENCIAS
- 1 Daniel Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreaos y Samuel Madden. 2013. El diseño y la implementación de sistemas modernos de bases de datos orientadas a columnas. https://doi.org/10.1561/9781601987556
- 2 Daniel Abadi, Samuel Madden y Miguel Ferreira. 2006. Integrating Compression and Execution in Column-Oriented Database Systems. En las actas de la ACM SIGMOD International Conference on Management of Data de 2006 (SIGMOD ‘06). 671–682.https://doi.org/10.1145/1142473.1142548
- 3 Anastassia Ailamaki, David J. DeWitt, Mark D. Hill y Marios Skounakis. 2001. Weaving Relations for Cache Performance. En Proceedings of the 27th International Conference on Very Large Data Bases (VLDB ‘01). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 169–180.
- 4 Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian y Doug Terry. 2022. Amazon Redshift Re-Invented. En las actas de la 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- 5 Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin y Matei Zaharia. 2022. Photon: A Fast Query Engine for Lakehouse Systems (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- 6 Philip A. Bernstein y Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- 7 Spyros Blanas, Yinan Li, y Jignesh M. Patel. 2011. Design and evaluation of main memory hash join algorithms for multi-core CPUs. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD ‘11). Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- 8 Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- 9 Burton H. Bloom. 1970. Space/Time Trade-Ofs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- 10 Peter Boncz, Thomas Neumann y Orri Erling. 2014. TPC-H analizado: mensajes ocultos y lecciones aprendidas de un benchmark influyente. En Performance Characterization and Benchmarking. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- 11 Peter Boncz, Marcin Zukowski y Niels Nes. 2005. MonetDB/X100: Hyper-Pipelining Query Execution. En CIDR.
- 12 Martin Burtscher y Paruj Ratanaworabhan. 2007. High Throughput Compression of Double-Precision Floating-Point Data. En la Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- 13 Jef Carpenter y Eben Hewitt. 2016. Cassandra: The Defnitive Guide (2.ª ed.). O’Reilly Media, Inc.
- 14 Bernadette Charron-Bost, Fernando Pedone y André Schiper (Eds.). 2010. Replication: Theory and Practice. Springer-Verlag.
- 15 chDB. 2024. chDB - un motor SQL OLAP embebido. Consultado el 2024-06-20 en https://github.com/chdb-io/chdb
- 16 ClickHouse. 2024. ClickBench: un benchmark para bases de datos analíticas. Recuperado el 2024-06-20 de https://github.com/ClickHouse/ClickBench
- 17 ClickHouse. 2024. ClickBench: Comparative Measurements. Consultado el 2024-06-20 en https://benchmark.clickhouse.com
- 18 ClickHouse. 2024. Hoja de ruta de ClickHouse 2024 (GitHub). Consultado el 2024-06-20 en https://github.com/ClickHouse/ClickHouse/issues/58392
- 19 ClickHouse. 2024. Benchmark de versiones de ClickHouse. Consultado el 2024-06-20 en https://github.com/ClickHouse/ClickBench/tree/main/versions
- 20 ClickHouse. 2024. Resultados del benchmark de versiones de ClickHouse. Consultado el 2024-06-20 en https://benchmark.clickhouse.com/versions/
- 21 Andrew Crotty. 2022. MgBench. Consultado el 2024-06-20 en https://github.com/ andrewcrotty/mgbench
- 22 Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis y Philipp Unterbrunner. 2016. The Snowfake Elastic Data Warehouse. En Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 215–226. https: //doi.org/10.1145/2882903.2903741
- 23 Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich y Wolfgang Lehner. 2019. From a Comprehensive Experimental Survey to a Cost-Based Selection Strategy for Lightweight Integer Compression Algorithms. ACM Trans. Database Syst. 44, 3, Artículo 9 (2019), 46 páginas. https://doi.org/10.1145/3323991
- 24 Philippe Dobbelaere y Kyumars Sheykh Esmaili. 2017. Kafka frente a RabbitMQ: un estudio comparativo de dos implementaciones de referencia de publicación/suscripción en la industria: artículo de la industria (DEBS ‘17). Association for Computing Machinery, New York, NY, USA, 227–238. https://doi.org/10.1145/3093742.3093908
- 25 Documentación de LLVM. 2024. Auto-Vectorization in LLVM. Consultado el 2024-06-20 en https://llvm.org/docs/Vectorizers.html
- 26 Siying Dong, Andrew Kryczka, Yanqin Jin y Michael Stumm. 2021. RocksDB: Evolution of Development Priorities in a Key-value Store Serving Large-scale Applications. ACM Transactions on Storage 17, 4, Artículo 26 (2021), 32 páginas. https://doi.org/10.1145/3483840
- 27 Markus Dreseler, Martin Boissier, Tilmann Rabl y Matthias Ufacker. 2020. Cuantificación de los cuellos de botella de TPC-H y de sus optimizaciones. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- 28 Ted Dunning. 2021. The t-digest: efficient estimates of distributions. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- 29 Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber y Hasso Plattner. 2016. Footprint Reduction and Uniqueness Enforcement with Hash Indices in SAP HANA. En Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- 30 Philippe Flajolet, Eric Fusy, Olivier Gandouet y Frederic Meunier. 2007. HyperLogLog: el análisis de un algoritmo de estimación de cardinalidad casi óptimo. En AofA: Analysis of Algorithms, Vol. DMTCS Proceedings vol. AH, 2007 Conference on Analysis of Algorithms (AofA 07). Discrete Mathematics and Theoretical Computer Science, 137–156. https://doi.org/10.46298/dmtcs.3545
- 31 Hector Garcia-Molina, Jefrey D. Ullman y Jennifer Widom. 2009. Database Systems - The Complete Book (2. Ed.).
- 32 Pawan Goyal, Harrick M. Vin, y Haichen Chen. 1996. Start-time fair queueing: a scheduling algorithm for integrated services packet switching networks. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- 33 Goetz Graefe. 1993. Query Evaluation Techniques for Large Databases. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- 34 Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li y Ravi Aringunram. 2018. Pinot: OLAP en tiempo real para 530 millones de usuarios. En Proceedings of the 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD ‘18). Association for Computing Machinery, New York, NY, USA, 583–594. https://doi.org/10.1145/3183713.3190661
- 35 ISO/IEC 9075-9:2001 2001. Tecnología de la información — Lenguaje de base de datos — SQL — Parte 9: Gestión de datos externos (SQL/MED). Norma. Organización Internacional de Normalización.
- 36 Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica y Matei Zaharia. 2023. Analyzing and Comparing Lakehouse Storage Systems. CIDR.
- 37 Project Jupyter. 2024. Jupyter Notebooks. Consultado el 2024-06-20 en https: //jupyter.org/
- 38 Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo y Peter Boncz. 2018. Everything You Always Wanted to Know about Compiled and Vectorized Queries but Were Afraid to Ask. Proc. VLDB Endow. 11, 13 (sep 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- 39 Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt y Pradeep Dubey. 2010. FAST: fast architecture sensitive tree search on modern CPUs and GPUs. En Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD ‘10). Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- 40 Donald E. Knuth. 1973. El arte de programar computadoras, Volumen III: Ordenación y búsqueda. Addison-Wesley.
- 41 André Kohn, Viktor Leis y Thomas Neumann. 2018. Adaptive Execution of Compiled Queries. In 2018 IEEE 34th International Conference on Data Engineering (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- 42 Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (aug 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- 43 Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann y Alfons Kemper. 2016. Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation. En Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- 44 Viktor Leis, Peter Boncz, Alfons Kemper y Thomas Neumann. 2014. Morseldriven parallelism: a NUMA-aware query evaluation framework for the manycore age. En las actas de la 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- 45 Viktor Leis, Alfons Kemper y Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. En 2013 IEEE 29th International Conference on Data Engineering (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- 46 Chunwei Liu, Anna Pavlenko, Matteo Interlandi y Brandon Haynes. 2023. Un análisis profundo de los formatos abiertos comunes para los SGBD analíticos. 16, 11 (jul 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- 47 Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, y Venkatesh Raghavan. 2021. Greenplum: A Hybrid Database for Transactional and Analytical Workloads (SIGMOD ‘21). Association for Computing Machinery, New York, NY, USA, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- 48 Roger MacNicol y Blaine French. 2004. Sybase IQ Multiplex - Designed for Analytics. En Proceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30 (Toronto, Canada) (VLDB ‘04). VLDB Endowment, 1227–1230.
- 49 Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky y Jef Shute. 2020. Dremel: A Decade of Interactive SQL Analysis at Web Scale. Proc. VLDB Endow. 13, 12 (ago 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- 50 Microsoft. 2024. Kusto Query Language. Consultado el 2024-06-20 en https: //github.com/microsoft/Kusto-Query-Language
- 51 Guido Moerkotte. 1998. Pequeños agregados materializados: una estructura de índice ligera para el almacenamiento de datos. En las actas de la 24.ª Conferencia Internacional sobre Bases de Datos Muy Grandes (VLDB ‘98). 476–487.
- 52 Jalal Mostafa, Sara Wehbi, Suren Chilingaryan, and Andreas Kopmann. 2022. SciTS: A Benchmark for Time-Series Databases in Scientifc Experiments and Industrial Internet of Things. En las actas de la 34.ª International Conference on Scientifc and Statistical Database Management (SSDBM ‘22). Artículo 12. https: //doi.org/10.1145/3538712.3538723
- 53 Thomas Neumann. 2011. efficiently Compiling efficient Query Plans for Modern Hardware. Proc. VLDB Endow. 4, 9 (jun 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- 54 Thomas Neumann y Michael J. Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. En 10th Conference on Innovative Data Systems Research, CIDR 2020, Ámsterdam, Países Bajos, 12-15 de enero de 2020, actas en línea. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- 55 Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD ‘15). Association for Computing Machinery, New York, NY, USA, 677–689. https://doi.org/10.1145/2723372. 2749436
- 56 LevelDB en GitHub. 2024. LevelDB. Consultado el 2024-06-20 en https://github. com/google/leveldb
- 57 Patrick O’Neil, Elizabeth O’Neil, Xuedong Chen y Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. En Performance Evaluation and Benchmarking. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- 58 Patrick E. O’Neil, Edward Y. C. Cheng, Dieter Gawlick y Elizabeth J. O’Neil. 1996. The log-structured Merge-Tree (LSM-tree). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- 59 Diego Ongaro y John Ousterhout. 2014. En busca de un algoritmo de consenso comprensible. En las actas de la USENIX Annual Technical Conference de 2014 (USENIX ATC’14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- 60 Patrick O’Neil, Edward Cheng, Dieter Gawlick y Elizabeth O’Neil. 1996. The Log-Structured Merge-Tree (LSM-Tree). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- 61 Pandas. 2024. DataFrames de Pandas. Recuperado el 2024-06-20 de https://pandas. pydata.org/
- 62 Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, y Biswapesh Chattopadhyay. 2022. Velox: Meta’s Unified Execution Engine. Proc. VLDB Endow. 15, 12 (ago. 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- 63 Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza y Kaushik Veeraraghavan. 2015. Gorilla: A Fast, Scalable, in-Memory Time Series Database. Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- 64 Orestis Polychroniou, Arun Raghavan y Kenneth A. Ross. 2015. Rethinking SIMD Vectorization for In-Memory Databases. En las actas de la 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- 65 PostgreSQL. 2024. PostgreSQL - Foreign Data Wrappers. Recuperado el 2024-06-20 de https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- 66 Mark Raasveldt, Pedro Holanda, Tim Gubner y Hannes Mühleisen. 2018. Fair Benchmarking Considered difficult: Common Pitfalls In Database Performance Testing. En las actas del Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). Artículo 2, 6 páginas. https://doi.org/10.1145/3209950.3209955
- 67 Mark Raasveldt y Hannes Mühleisen. 2019. DuckDB: An Embeddable Analytical Database (SIGMOD ‘19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869.3320212
- 68 Jun Rao and Kenneth A. Ross. 1999. Cache Conscious Indexing for Decision-Support in Main Memory. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB ‘99). San Francisco, CA, USA, 78–89.
- 69 Navin C. Sabharwal and Piyush Kant Pandey. 2020. Uso del lenguaje de consulta de Prometheus (PromQL). En Monitorización de microservicios y aplicaciones en contenedores. https://doi.org/10.1007/978-1-4842-6216-0_5
- 70 Todd W. Schneider. 2022. New York City Taxi and For-Hire Vehicle Data. Consultado el 2024-06-20 en https://github.com/toddwschneider/nyc-taxi-data
- 71 Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran y Stan Zdonik. 2005. C-Store: un SGBD orientado a columna. En las actas de la 31.ª Conferencia Internacional sobre Bases de Datos de Gran Tamaño (VLDB ‘05). 553–564.
- 72 Teradata. 2024. Teradata Database. Consultado el 2024-06-20 en https://www. teradata.com/resources/datasheets/teradata-database
- 73 Frederik Transier. 2010. Algorithms and Data Structures for In-Memory Text Search Engines. Tesis de doctorado. https://doi.org/10.5445/IR/1000015824
- 74 Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann y Manuel Then. 2018. Get Real: How Benchmarks Fail to Represent the Real World. En las actas del Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). Artículo 1, 6 páginas. https://doi.org/10.1145/3209950.3209952
- 75 Sitio web de LZ4. 2024. LZ4. Consultado el 2024-06-20 en https://lz4.org/
- 76 Sitio web de PRQL. 2024. PRQL. Consultado el 2024-06-20 en https://prql-lang.org 77 Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000. The Implementation and Performance of Compressed Databases. SIGMOD Rec.
- 29, 3 (sep 2000), 55–67. https://doi.org/10.1145/362084.362137 78 Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. Druid: Un almacén de datos analíticos en tiempo real. En Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- 79 Tianqi Zheng, Zhibin Zhang, y Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- 80 Jingren Zhou y Kenneth A. Ross. 2002. Implementing Database Operations Using SIMD Instructions. En las actas de la 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘02). 145–156. https://doi.org/10. 1145/564691.564709
- 81 Marcin Zukowski, Sandor Heman, Niels Nes y Peter Boncz. 2006. Super-Scalar RAM-CPU Cache Compression. En Proceedings of the 22nd International Conference on Data Engineering (ICDE ‘06). 59. https://doi.org/10.1109/ICDE. 2006.150