要旨
1 はじめに
- 高いインジェスト率を伴う巨大なデータセット。Web analytics、金融、e-commerce などの分野における多くのデータ駆動型アプリケーションは、巨大で継続的に増加するデータ量を特徴としています。こうした巨大なデータセットを扱うには、分析データベースは効率的な索引付けと圧縮戦略を提供するだけでなく、単一のサーバーでは数十テラバイトのストレージに限られるため、データを複数ノードに分散できること (スケールアウト) も必要です。さらに、リアルタイムの洞察では、過去のデータよりも最新のデータの方が重要であることが少なくありません。その結果、分析データベースには、新しいデータを継続的に高いレートで、あるいはバースト的に取り込めることに加え、並行して実行されるレポート用クエリを遅くすることなく、過去データの優先度を継続的に下げること (たとえば集約やアーカイブ) が求められます。
- 低レイテンシが求められる多数の同時クエリ。クエリは一般に、アドホックなもの (たとえば探索的データ分析) と定常的なもの (たとえば定期的な dashboard クエリ) に分類できます。ユースケースの対話性が高いほど、より低いクエリレイテンシが求められ、クエリ最適化と実行における課題が大きくなります。定常的なクエリではさらに、workload に合わせてデータベースの物理レイアウトを最適化する機会も得られます。そのため、データベースは、頻出クエリを最適化できるプルーニング手法を提供すべきです。また、クエリの優先度に応じて、多数のクエリが同時に実行されている場合でも、CPU、メモリ、ディスク、ネットワーク I/O などの共有システムリソースへの均等または優先的なアクセスを提供しなければなりません。
- 多様なデータストア、保存場所、フォーマットの環境。既存のデータアーキテクチャと統合するために、現代の分析データベースは、あらゆるシステム、場所、フォーマットにある外部データを読み書きできるよう、高い開放性を備えている必要があります。
- 性能の詳細な分析を支援する、使いやすいクエリ言語。OLAP データベースの実運用では、さらに「ソフト」な要件も生じます。たとえば、ニッチなプログラミング言語ではなく、ユーザーはしばしば、ネストしたデータ型と幅広い通常の関数、集約関数、ウィンドウ関数を備えた表現力の高い SQL方言 を通じてデータベースとやり取りすることを好みます。また、分析データベースは、システム全体や個々のクエリの性能を詳しく調べるための高度なツールも提供すべきです。
- 業界水準の堅牢性と柔軟なデプロイ。汎用ハードウェアは信頼性が高いとは限らないため、データベースはノード障害に対する堅牢性を確保するためにデータのレプリケーションを提供しなければなりません。また、データベースは古いラップトップから高性能なサーバーまで、あらゆるハードウェア上で動作する必要があります。最後に、JVM ベースのプログラムにおけるガーベジコレクションのオーバーヘッドを避け、ベアメタル性能 (たとえば SIMD) を実現するために、データベースは理想的には対象プラットフォーム向けのネイティブバイナリとしてデプロイされます。

2 アーキテクチャ
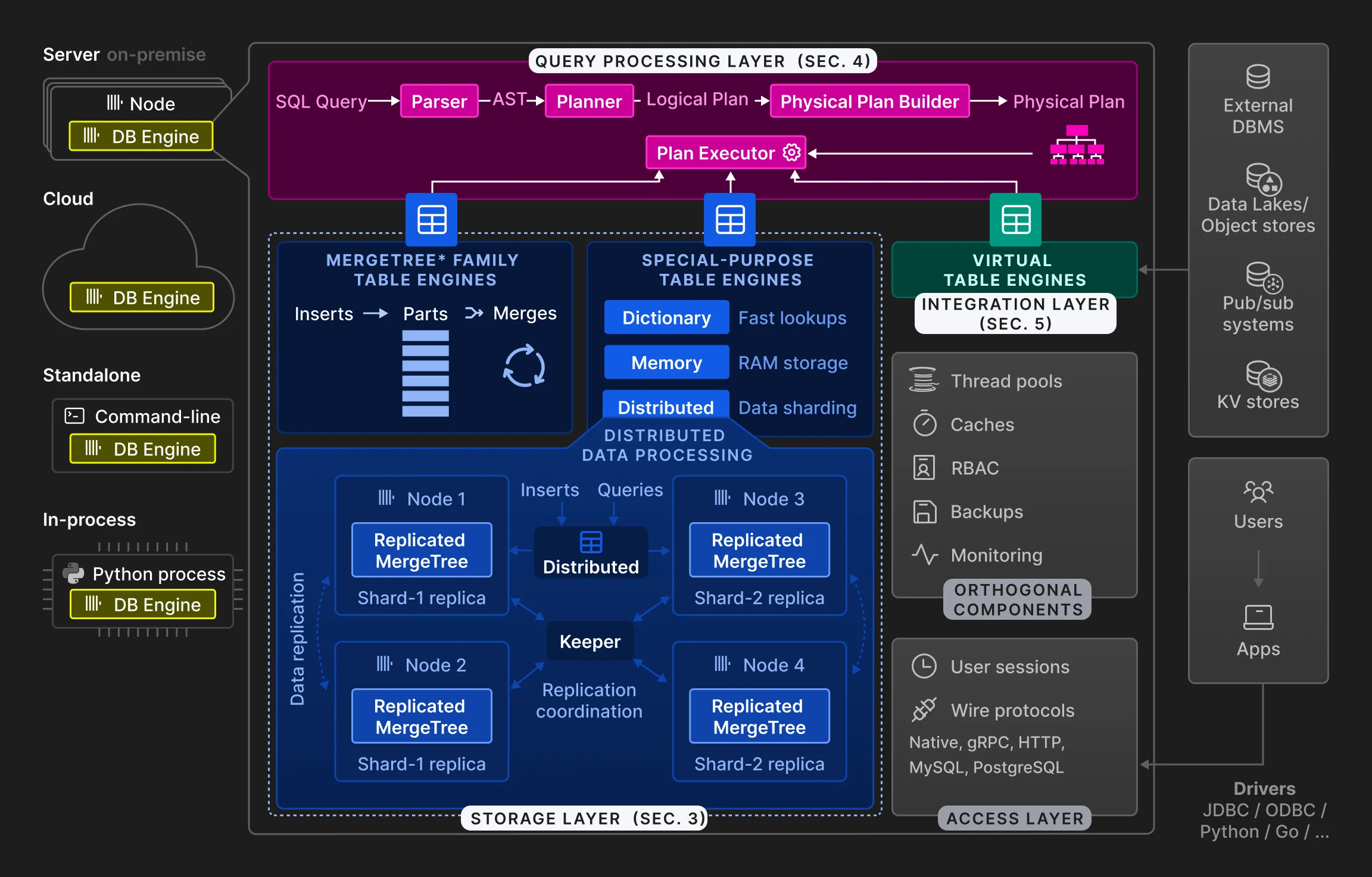
3 ストレージ層
この節では、ClickHouseのネイティブなストレージフォーマットである MergeTree* テーブルエンジンについて説明します。まず、そのディスク上の表現を説明し、続いて ClickHouse における 3 つのデータプルーニング手法を取り上げます。その後、同時実行中の insert に影響を与えることなくデータを継続的に変換する merge 戦略を紹介します。最後に、update と delete の実装方法に加え、データの重複排除、データのレプリケーション、および ACID 準拠について説明します。3.1 ディスク上のフォーマット
MergeTree* テーブルエンジンの各テーブルは、不変なテーブルパーツの集合として構成されます。パーツは、行のまとまりがテーブルに挿入されるたびに作成されます。パーツは自己完結型であり、その内容を解釈するために必要なすべてのメタデータを含むため、中央カタログに追加でルックアップしなくても扱えます。テーブルごとのパーツ数を少なく保つため、バックグラウンドのマージジョブが複数の小さなパーツを定期的に 1 つの大きなパーツへ統合し、設定可能なパーツサイズ (デフォルトは 150 GB) に達するまでこれを続けます。パーツはテーブルの主キーカラムでソートされているため (Section 3.2) を参照) 、マージには効率的な k-way マージソート [40] が用いられます。元のパーツは非アクティブとしてマークされ、参照カウントがゼロ、つまりそれらを参照するクエリがなくなると、最終的に削除されます。 行は 2 つのモードで挿入できます。同期挿入モードでは、各 INSERT ステートメントごとに新しいパーツが作成され、テーブルに追加されます。マージのオーバーヘッドを最小限に抑えるため、データベースクライアントはタプルをまとめて挿入することが推奨されます。たとえば、一度に 20,000 行を挿入します。ただし、データをリアルタイムで分析する必要がある場合、クライアント側のバッチ処理による遅延はしばしば許容できません。たとえば、オブザーバビリティのユースケースでは、何千もの監視エージェントが少量のイベントデータやメトリクスデータを継続的に送信することがよくあります。このようなシナリオでは非同期挿入モードを利用できます。このモードでは、ClickHouse は同じテーブルに対する複数の受信 INSERT の行をバッファリングし、バッファサイズが設定可能なしきい値を超えるか、タイムアウトになるまで新しいパーツを作成しません。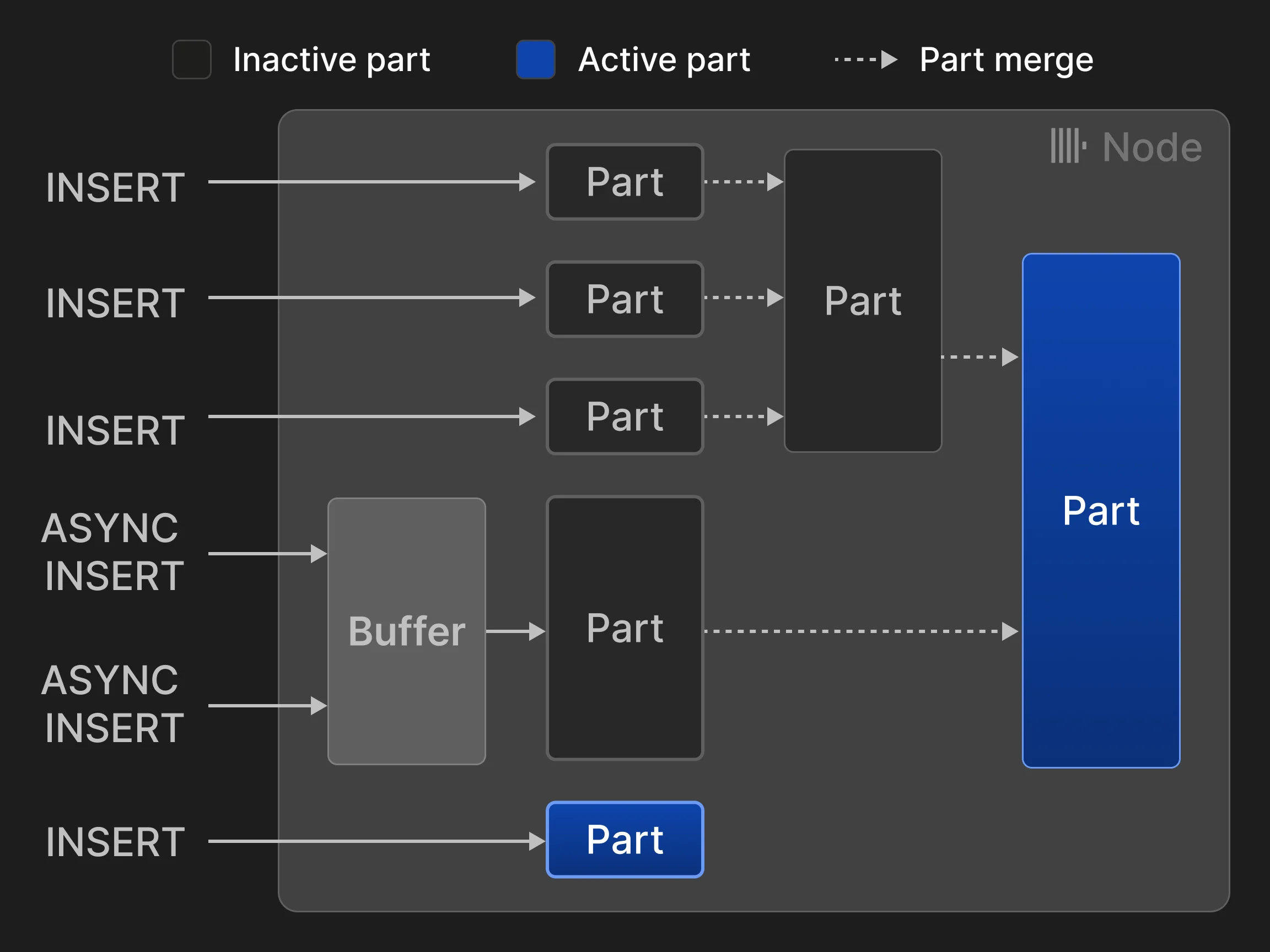
3.2 データプルーニング
ほとんどのユースケースでは、1つのクエリに答えるためだけにPB規模のデータをスキャンするのは、遅すぎるうえコストもかかりすぎます。ClickHouseは、検索時に大半の行をスキップし、クエリを大幅に高速化できる3つのデータプルーニング手法をサポートしています。 まず、ユーザーはテーブルに主キー索引を定義できます。主キーカラムは、各パーツ内での行のソート順を決定します。つまり、この索引はローカルにクラスター化されています。さらにClickHouseは各パーツについて、各グラニュールの先頭行の主キーカラム値から、そのグラニュールのidへの対応を保持します。つまり、この索引はスパースです [31]。このデータ構造は通常、全体をメモリ内に保持できるほど小さく、たとえば810万行の索引付けに必要なエントリは1000件だけです。主キーの主な目的は、逐次スキャンではなく二分探索を使って、頻繁にフィルタされるカラムに対する等価条件や範囲条件を評価することです (Section 4.4)) 。さらに、このローカルなソート順は、パーツのマージやクエリ最適化にも活用できます。たとえば、ソートベースの集約や、主キーカラムがソートカラムのプレフィックスを成している場合に、物理実行計画からソート演算子を取り除くことが可能です。 Figure 4は、ページインプレッション統計を持つテーブルのカラムEventTime上の主キー索引を示しています。クエリ内の範囲条件に一致するグラニュールは、EventTimeを逐次スキャンする代わりに、主キー索引を二分探索することで見つけられます。
3.3 マージ時のデータ変換
ビジネスインテリジェンスやオブザーバビリティのユースケースでは、継続的に高いレート、あるいは突発的なバーストで生成されるデータを扱う必要がよくあります。また、意味のあるリアルタイムのインサイトを得るうえでは、通常、過去のデータよりも最近生成されたデータのほうが重要です。このようなユースケースでは、データベースは高いデータインジェスト率を維持しつつ、集計やデータのエージングといった手法によって履歴データの量を継続的に削減できる必要があります。ClickHouse では、さまざまなマージ戦略を用いて既存データを継続的かつ段階的に変換できます。マージ時のデータ変換は INSERT ステートメントのパフォーマンスを損ないませんが、テーブルに不要な値 (たとえば古い値や未集計の値) が一切含まれないことまでは保証できません。必要に応じて、SELECT ステートメントでキーワード FINAL を指定することで、すべてのマージ時変換をクエリ時に適用できます。 Replacing merges は、タプルを含むパーツの作成タイムスタンプに基づいて、最後に挿入されたバージョンのタプルだけを保持し、古いバージョンを削除します。タプルは、同じ主キーカラム値を持つ場合に同一とみなされます。どのタプルを保持するかを明示的に制御するために、比較用の特別なバージョンカラムを指定することもできます。Replacing merges は一般に、マージ時の更新メカニズムとして (通常は更新が頻繁なユースケースで) 使用されるほか、挿入時のデータ重複排除 (Section 3.5)) の代替として使われることもあります。 Aggregating merges は、主キーカラム値が同じ行を 1 つの集計行にまとめます。主キー以外のカラムは、要約値を保持する部分集計状態でなければなりません。2 つの部分集計状態、たとえば avg() のための sum と count は、新しい部分集計状態に結合されます。Aggregating merges は、通常のテーブルではなく materialized view で使われるのが一般的です。materialized view は、ソーステーブルに対する変換クエリに基づいて作成されます。他のデータベースとは異なり、ClickHouse は materialized view をソーステーブル全体の内容で定期的に更新しません。代わりに、ソーステーブルに新しいパーツが挿入されるたびに、その変換クエリの結果で materialized view が段階的に更新されます。 図 5 は、ページインプレッション統計を持つテーブル上に定義された materialized view を示しています。ソーステーブルに新たに挿入されたパーツに対して、変換クエリは region ごとにグループ化して最大および平均レイテンシを計算し、その結果を materialized view に挿入します。接尾辞 -State を持つ集計関数 avg() と max() は、実際の結果ではなく部分集計状態を返します。materialized view に定義された aggregating merge は、異なるパーツ内の部分集計状態を継続的に結合します。最終結果を得るには、ユーザーは -Merge 接尾辞を付けた avg() および max() を使って、materialized view 内の部分集計状態を統合します。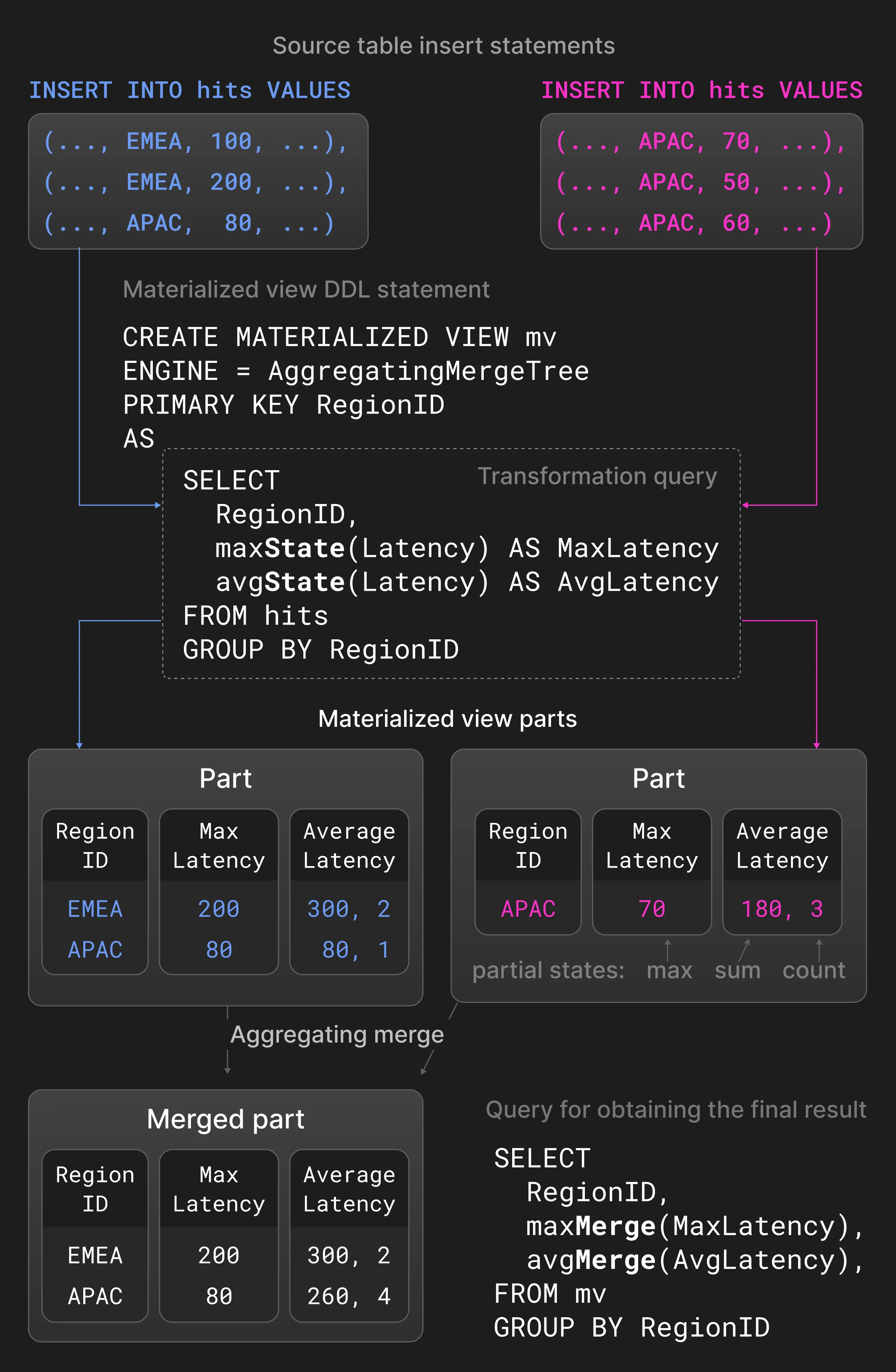
3.4 更新と削除
MergeTree* テーブルエンジンは追記専用のワークロードに適した設計ですが、規制遵守などの理由から、既存データを必要に応じて変更しなければならないユースケースもあります。データを更新または削除する方法は 2 つあり、どちらも並行する INSERT をブロックしません。 ミューテーション は、テーブルのすべてのパーツをその場で書き換えます。テーブル (delete) またはカラム (update) のサイズが一時的に 2 倍になるのを防ぐため、この操作は非アトミックです。つまり、並行する SELECT ステートメントは、変更済みパーツと未変更パーツの両方を読み取る可能性があります。ミューテーションでは、処理の完了時点でデータが物理的に変更されていることが保証されます。削除ミューテーションは、すべてのパーツ内のすべてのカラムを書き換えるため、依然としてコストが高いままです。 代替手段として、論理削除 は、行が削除されているかどうかを示す内部のビットマップカラムだけを更新します。ClickHouse は SELECT クエリにビットマップカラムに対する追加のフィルタを適用し、削除された行を結果から除外します。削除された行が物理的に除去されるのは、将来のどこかの時点で通常のマージが行われたときだけです。カラム数によっては、論理削除は SELECT が遅くなる代わりに、ミューテーションより大幅に高速になる場合があります。 同じテーブルに対する更新および削除操作は、論理的な競合を避けるため、まれにしか行われず、直列に実行されることが想定されています。3.5 冪等な挿入
実運用で頻繁に発生する問題の 1 つは、テーブルに挿入するためのデータをサーバーに送信した後で接続タイムアウトが発生した場合に、クライアントがそれをどう扱うべきかという点です。この状況では、データが正常に挿入されたのかどうかをクライアントが判別するのは困難です。従来、この問題はクライアントからサーバーへデータを再送し、重複した挿入を主キーや一意制約で拒否させることで解決されてきました。データベースは、二分木 [39, [68]](#page-13-16)、ラジックス木 [45]、またはハッシュテーブル [29] に基づく索引構造を用いて、必要なポイントルックアップを高速に実行します。これらのデータ構造はすべてのタプルに索引を付けるため、大規模なデータセットや高い取り込みレートでは、領域および更新のオーバーヘッドが無視できなくなります。 ClickHouse は、各 insert が最終的に 1 つのパーツを作成するという事実に基づく、より軽量な代替手段を提供します。より具体的には、サーバーは直近に挿入された N 個のパーツ (たとえば N=100) のハッシュを保持し、既知のハッシュを持つパーツの再挿入を無視します。非レプリケートテーブルとレプリケートテーブルのハッシュは、それぞれローカルと Keeper に保存されます。その結果、insert は冪等になり、つまりクライアントはタイムアウト後に同じ行のバッチをそのまま再送するだけで、サーバー側で重複排除が行われると考えてよくなります。重複排除プロセスをより細かく制御するために、クライアントはオプションで、パーツハッシュとして機能する挿入トークンを指定できます。ハッシュベースの重複排除では、新しい行のハッシュ化に伴うオーバーヘッドは発生するものの、ハッシュの保存と比較にかかるコストはごくわずかです。3.6 データレプリケーション
レプリケーションは高可用性 (ノード障害に対する耐性) の前提条件ですが、負荷分散や無停止アップグレードにも利用されます [14]。ClickHouse では、レプリケーションはテーブル状態という考え方に基づいており、テーブル状態はテーブルパーツの集合 (Section 3.1)) と、カラム名や型などのテーブルメタデータで構成されます。ノードは 3 つの操作によってテーブル状態を進めます。1. insert は状態に新しいパーツを追加します。2. マージ は状態に新しいパーツを追加し、既存のパーツを状態から削除します。3. ミューテーション と DDL ステートメントは、具体的な操作に応じて、パーツの追加、パーツの削除、テーブルメタデータの変更を行います。これらの操作は単一ノード上でローカルに実行され、その状態遷移の列がグローバルなレプリケーションログに記録されます。 レプリケーションログは、通常は 3 つの ClickHouse Keeper プロセスから成るアンサンブルによって管理されます。これらのプロセスは、Raft コンセンサスアルゴリズム [59] を用いて、ClickHouse ノードのクラスターに対して分散型で耐障害性のある協調レイヤーを提供します。クラスター内のすべてのノードは、初期状態ではレプリケーションログ内の同じ位置を指しています。ノードがローカルで insert、マージ、ミューテーション、および DDL ステートメントを実行する一方で、レプリケーションログは他のすべてのノード上で非同期にリプレイされます。その結果、レプリケートテーブルは結果整合性にとどまります。つまり、ノードは最新の状態へ収束する途中で、一時的に古いテーブル状態を読み取ることがあります。前述の操作の多くは、ノードのクォーラム (たとえばノードの過半数または全ノード) が新しい状態を採用するまで、同期的に実行することもできます。 例として、Figure 6 は、3 つの ClickHouse ノードから成るクラスター内の、初期状態では空のレプリケートテーブルを示しています。まず Node 1 が 2 つの insert ステートメントを受け取り、それらを Keeper アンサンブルに保存されているレプリケーションログに記録します ( 1 2 ) 。次に、Node 2 は最初のログエントリを取得し ( 3 ) 、Node 1 から新しいパーツをダウンロードして ( 4 ) 、そのエントリをリプレイします。一方、Node 3 は両方のログエントリをリプレイします ( 3 4 5 6 ) 。最後に、Node 3 は 2 つのパーツを マージ して新しいパーツを作成し、入力パーツを削除して、その マージ エントリをレプリケーションログに記録します ( 7 ) 。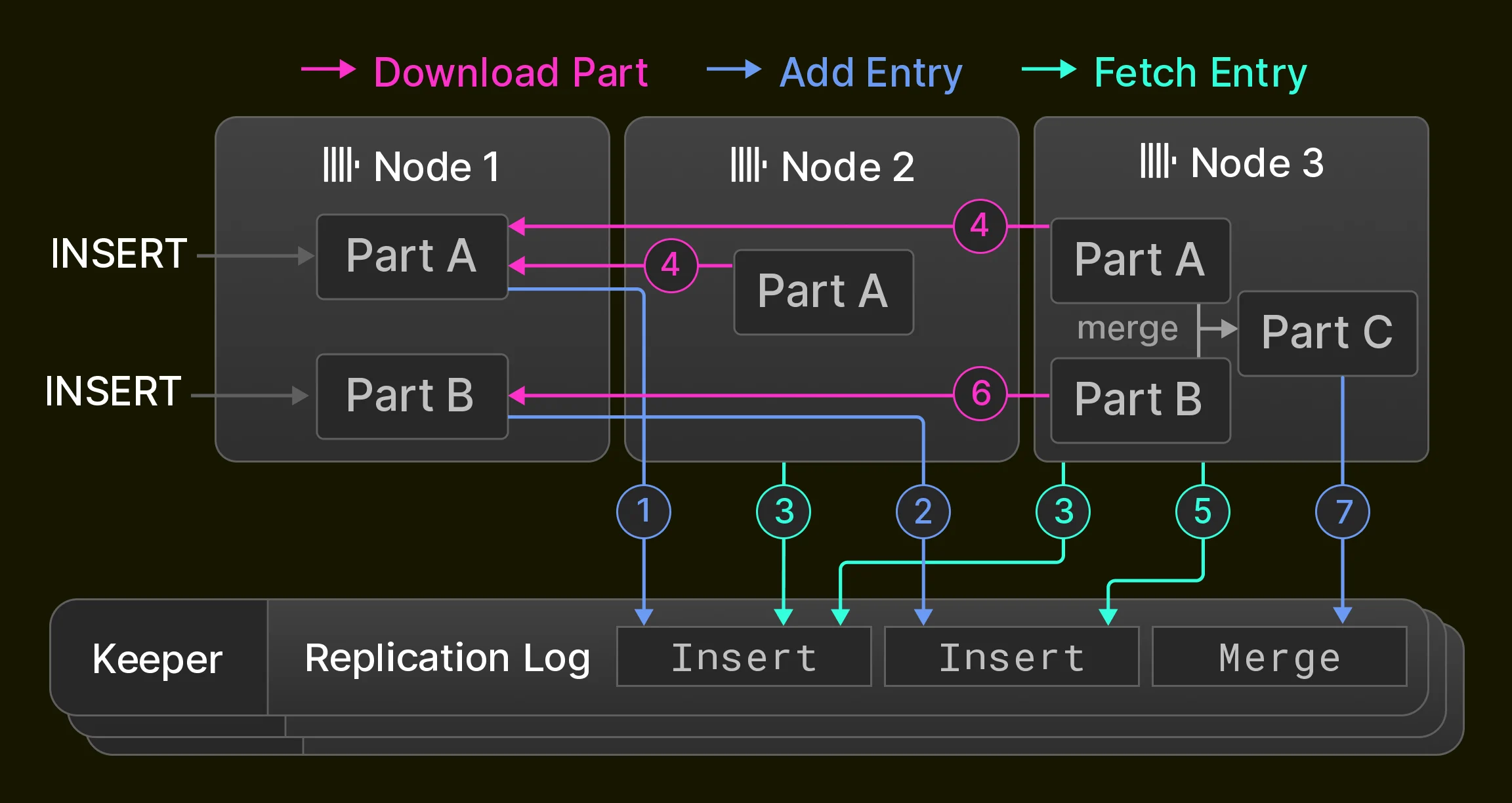
3.7 ACID 準拠
同時実行の読み取りおよび書き込み操作のパフォーマンスを最大化するため、ClickHouse は可能な限りラッチングを避けています。クエリは、クエリ開始時点で作成された、関係するすべてのテーブル内のすべてのパーツのスナップショットに対して実行されます。これにより、並列 INSERT や マージ (Section 3.1) によって新たに作成されたパーツは実行に含まれません。さらに、パーツが同時に変更または削除されることを防ぐため (Section 3.4)) 、処理対象パーツの参照カウントはクエリの実行中インクリメントされます。形式的には、これはバージョン管理されたパーツに基づく MVCC の一種 [6] によって実現されるスナップショット分離に相当します。その結果、スナップショット取得時に同時実行の書き込みがそれぞれ単一のパーツにしか影響しないというまれなケースを除き、ステートメントは一般に ACID 準拠ではありません。 実際には、ClickHouse の書き込み負荷が高い意思決定系ユースケースの多くでは、停電時に新しいデータが失われるわずかなリスクも許容されます。これを踏まえ、データベースはデフォルトでは新たに挿入されたパーツの disk へのコミット (fsync) を強制せず、その代わりにアトミック性を犠牲にして、カーネルが書き込みをまとめて処理できるようにしています。4 クエリ処理レイヤー
4.1 SIMD 並列化
4.2 マルチコア並列化
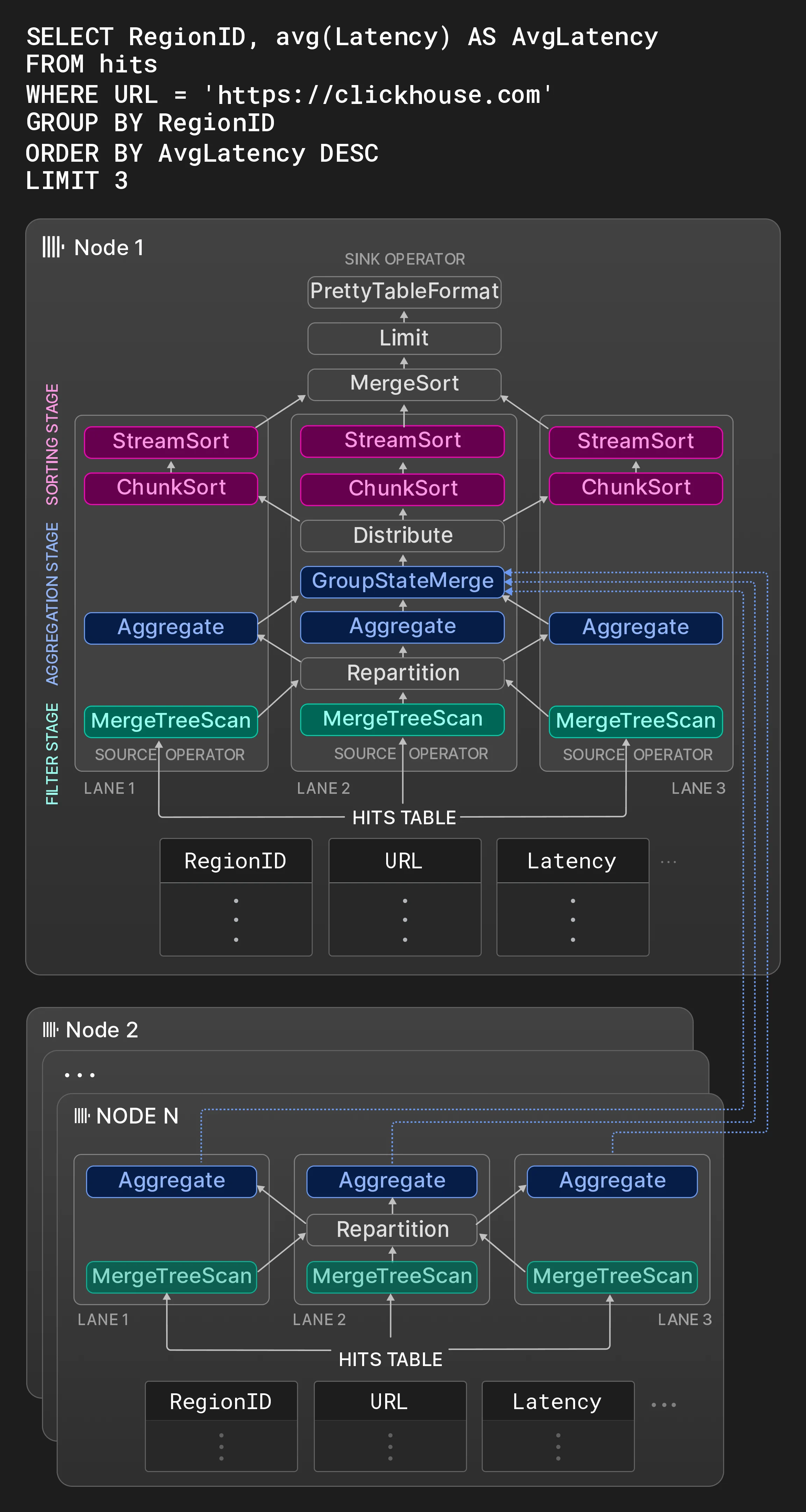
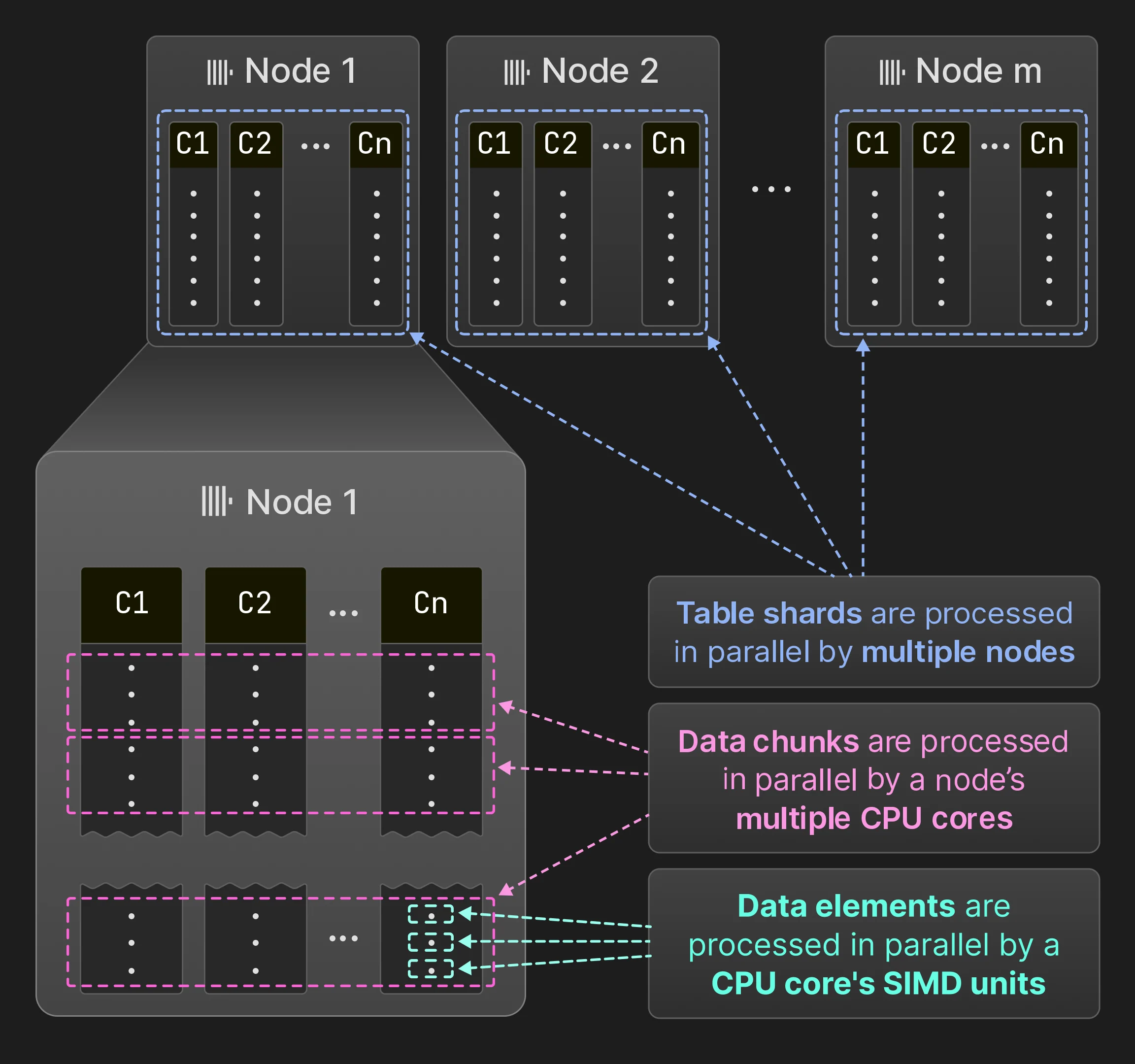
4.3 マルチノード並列化
4.4 包括的な性能最適化
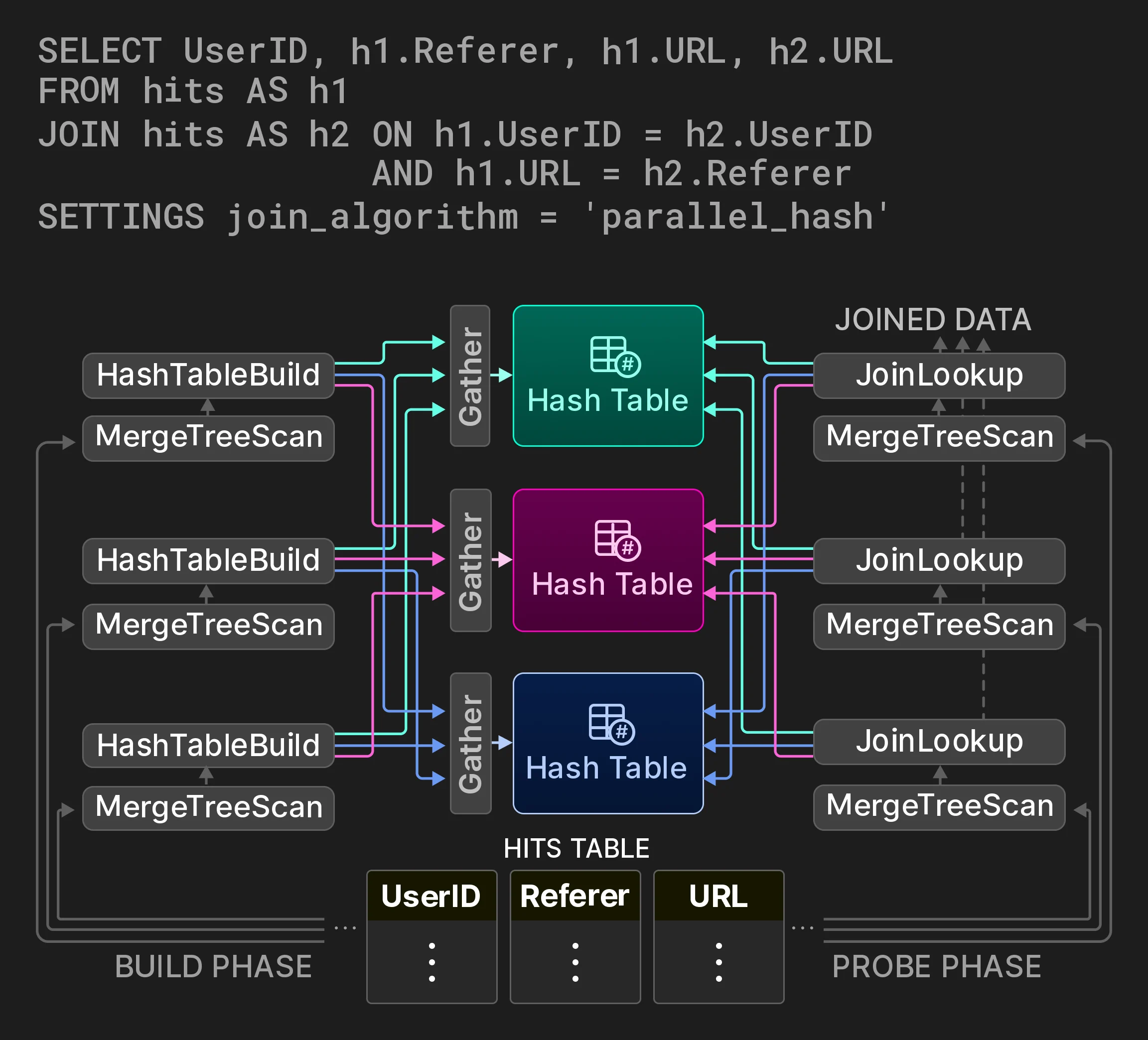
この節では、クエリ実行のさまざまな段階で適用される主要な性能最適化をいくつか紹介します。 クエリ最適化。最初の一連の最適化は、クエリの AST から得られる意味的なクエリ表現に対して適用されます。こうした最適化の例としては、定数畳み込み (例: concat(lower(‘a’),upper(‘b’)) は ‘aB’ になる) 、特定の 集約 関数からのスカラー値の抽出 (例: sum(a2) は 2 * sum(a) になる) 、共通部分式除去、等値フィルタの選言を IN リストに変換すること (例: x=c OR x=d は x IN (c,d) になる) などがあります。最適化後の意味的クエリ表現は、続いて論理演算子プランに変換されます。論理プランに対する最適化には、filter pushdown や、どちらのコストが高いと見積もられるかに応じた関数評価とソート手順の並べ替えが含まれます。最後に、論理クエリプランは物理演算子プランに変換されます。この変換では、対象となるテーブルエンジンの特性を活用できます。たとえば MergeTree-table engine の場合、ORDER BY カラムが主キーのプレフィックスを構成していれば、データをディスク上の順序で読み取れるため、ソート演算子をプランから除去できます。また、集約 における grouping カラムが主キーのプレフィックスを構成している場合、ClickHouse は sort 集約 [33] を使用できます。つまり、あらかじめソートされた入力内で同じ値が連続する部分を直接集約します。hash 集約 と比べると、sort 集約 はメモリ消費が大幅に少なく、その連続部分の処理が終わるとすぐに集約値を次の演算子に渡せます。 クエリコンパイル。ClickHouse は LLVM に基づくクエリコンパイル を用いて、隣接するプラン演算子を動的に融合します [38, [53]](#page-13-0)。たとえば、式 a * b + c + 1 は、3 つの演算子ではなく 1 つの演算子にまとめることができます。式に加えて、ClickHouse は複数の 集約 関数を一度に評価するため (つまり GROUP BY のため) や、複数のソートキーによるソートのためにもコンパイルを利用します。クエリコンパイルは仮想呼び出しの回数を減らし、データをレジスタや CPU cache に保持し、実行されるコード量が少なくなることで分岐予測にも役立ちます。さらに、実行時コンパイルにより、コンパイラに実装されている論理最適化や peephole 最適化など、さまざまな最適化が可能になり、その環境で利用可能な最速の CPU 命令も使えるようになります。コンパイルは、同じ通常の式、集約 式、またはソート式が、異なるクエリで設定可能な回数を超えて実行された場合にのみ開始されます。コンパイル済みのクエリ演算子は cache され、今後のクエリで再利用できます。[7] 主キー索引の評価。ClickHouse は、条件の連言標準形に含まれる filter clause の部分集合が主キーカラムのプレフィックスを構成している場合、主キー索引を使って WHERE 条件を評価します。主キー索引は、キー値の辞書順にソートされた範囲に対して左から右へ解析されます。主キーカラムに対応する filter clause は三値論理で評価されます。すなわち、その範囲内の値に対して、すべて真、すべて偽、または真と偽が混在、のいずれかです。最後のケースでは、その範囲は部分範囲に分割され、再帰的に解析されます。filter 条件内の関数に対しても追加の最適化があります。第一に、関数には単調性を表す特性があります。たとえば toDayOfMonth(date) は 1 か月の範囲内では区分的に単調です。単調性の特性により、ソート済みの入力キー値範囲に対して、その関数がソート済みの結果を生成するかどうかを推論できます。第二に、一部の関数は、与えられた関数結果の逆像を計算できます。これは、キーカラムに対する関数呼び出しと定数との比較を、キーカラムの値とその逆像との比較に置き換えるために使われます。たとえば、toYear(k) = 2024 は k >= 2024-01-01 && k < 2025-01-01 に置き換えられます。 データスキッピング。ClickHouse は、3.2 節で示したデータ構造を用いて、クエリ実行時のデータ読み取りを回避しようとします。さらに、異なるカラムに対するフィルタは、ヒューリスティクスおよび (任意の) カラム STATISTICS に基づく推定 selectivity の高い順に、順次評価されます。少なくとも 1 つの一致する行を含む data chunk だけが、次の predicate に渡されます。これにより、predicate ごとに、読み取るデータ量と実行すべき計算回数が徐々に減少します。この最適化は、少なくとも 1 つの高選択性の predicate が存在する場合にのみ適用されます。そうでなければ、すべての predicate を並列に評価する場合と比べて、クエリの latency が悪化してしまうためです。 ハッシュテーブル。ハッシュテーブルは、集約 やハッシュ結合における基本的なデータ構造です。適切な種類のハッシュテーブルを選ぶことは、性能を左右する重要な要素です。ClickHouse は、ハッシュ関数、アロケータ、セル型、リサイズポリシーを可変要素とする汎用ハッシュテーブルテンプレートから、さまざまなハッシュテーブルを 生成 します (2024 年 3 月時点で 30 種類以上) 。グループ化カラムのデータ型、推定されるハッシュテーブルのカーディナリティ、そのほかの要因に応じて、各クエリ演算子ごとに最も高速なハッシュテーブルが個別に選択されます。ハッシュテーブルに実装されている追加の最適化には、次のものがあります。- 巨大なキー集合をサポートするための、256 個のサブテーブルから成る 2 レベル構成 (ハッシュの先頭 1 バイトに基づく) 、
- 4 つのサブテーブルを持ち、文字列長に応じて異なるハッシュ関数を使う文字列用ハッシュテーブル [79]、
- キー数が少ない場合に、キーを直接バケット索引として使用する (つまりハッシュ化しない) ルックアップテーブル、
- 比較コストが高い場合 (例: 文字列、AST) に衝突解決を高速化する、ハッシュ値を埋め込んだ値、
- 不要なリサイズを避けるため、実行時統計から予測したサイズに基づいてハッシュテーブルを作成すること、
- 作成と破棄のライフサイクルが同じ複数の小さなハッシュテーブルを、単一のメモリスラブ上に割り当てること、
- ハッシュマップごとおよびセルごとのバージョンカウンターを用いて、再利用のためにハッシュテーブルを即座にクリアすること、
- キーのハッシュ化後の値取得を高速化するために CPU prefetch (__builtin_prefetch) を使用すること。
4.5 ワークロード分離
ClickHouse では、同時実行制御、メモリ使用量の制限、I/O スケジューリングにより、クエリをワークロードクラスごとに分離できます。特定のワークロードクラスに対して共有リソース (CPU コア、DRAM、ディスク I/O、ネットワーク I/O) の制限を設定することで、それらのクエリが他の重要な業務クエリに影響しないようにできます。 同時実行制御は、同時実行クエリ数が多い状況でスレッドの過剰割り当てを防ぎます。具体的には、クエリごとのワーカースレッド数が、使用可能な CPU コア数に対する指定比率に基づいて動的に調整されます。 ClickHouse は、server、user、query の各レベルでメモリ割り当てのバイト数を追跡し、柔軟なメモリ使用量制限を設定できるようにします。メモリオーバーコミットにより、他のクエリのメモリ制限を確保しつつ、クエリは保証されたメモリを超える追加の空きメモリを利用できます。さらに、集約、ソート、join clauses のメモリ使用量も制限でき、メモリ制限を超えた場合は外部アルゴリズムへのフォールバックが行われます。 最後に、I/O スケジューリングにより、最大帯域幅、進行中のリクエスト数、ポリシー (例: FIFO、SFC [32]) に基づいて、ワークロードクラスごとにローカルおよびリモートのディスクアクセスを制限できます。5 インテグレーション レイヤー
リアルタイムの意思決定アプリケーションでは、多くの場合、複数の場所にあるデータに効率よく低レイテンシでアクセスできることが求められます。外部データを OLAP データベースで利用可能にする方法には、2 つのアプローチがあります。プッシュ型のデータアクセスでは、サードパーティのコンポーネントがデータベースと外部データストアの橋渡し役となります。その一例が、リモートデータを宛先システムへプッシュする専用の extract-transform-load (ETL) ツールです。プル型モデルでは、データベース自体がリモートのデータソースに接続し、クエリのためにデータをローカルテーブルへ取り込んだり、データをリモートシステムへエクスポートしたりします。一般に、プッシュ型のアプローチはより汎用的で広く使われていますが、その分アーキテクチャは大きくなり、スケーラビリティ上のボトルネックも生じます。これに対して、データベースに直接組み込まれたリモート接続機能は、ローカルデータとリモートデータの結合などの興味深い機能を提供しつつ、全体のアーキテクチャをシンプルに保ち、インサイト獲得までの時間を短縮します。 この節の残りでは、リモート環境にあるデータにアクセスするための、ClickHouse におけるプル型のデータ統合手法を見ていきます。なお、SQL データベースにおけるリモート接続という考え方自体は新しいものではありません。たとえば、2001 年に導入され、2011 年から PostgreSQL で実装されている SQL/MED 標準 [35] [65] では、外部データを管理するための統一インターフェイスとして foreign data wrappers が提案されています。他のデータストアやストレージフォーマットとの最大限の相互運用性は、ClickHouse の設計目標の 1 つです。私たちの知る限り、2024 年 3 月時点で ClickHouse は、分析データベース全体の中でもっとも多くの組み込みデータ統合オプションを提供しています。 外部接続。ClickHouse は、ODBC、MySQL、PostgreSQL、SQLite、Kafka、Hive、MongoDB、Redis、S3/GCP/Azure のオブジェクトストア、および各種データレイクを含む外部システムやストレージロケーションに接続するために、50+ のインテグレーション テーブル関数とエンジンを提供しています。さらに、これらは次のボーナス図に示すカテゴリに分類できます (元の VLDB 論文には含まれていません) 。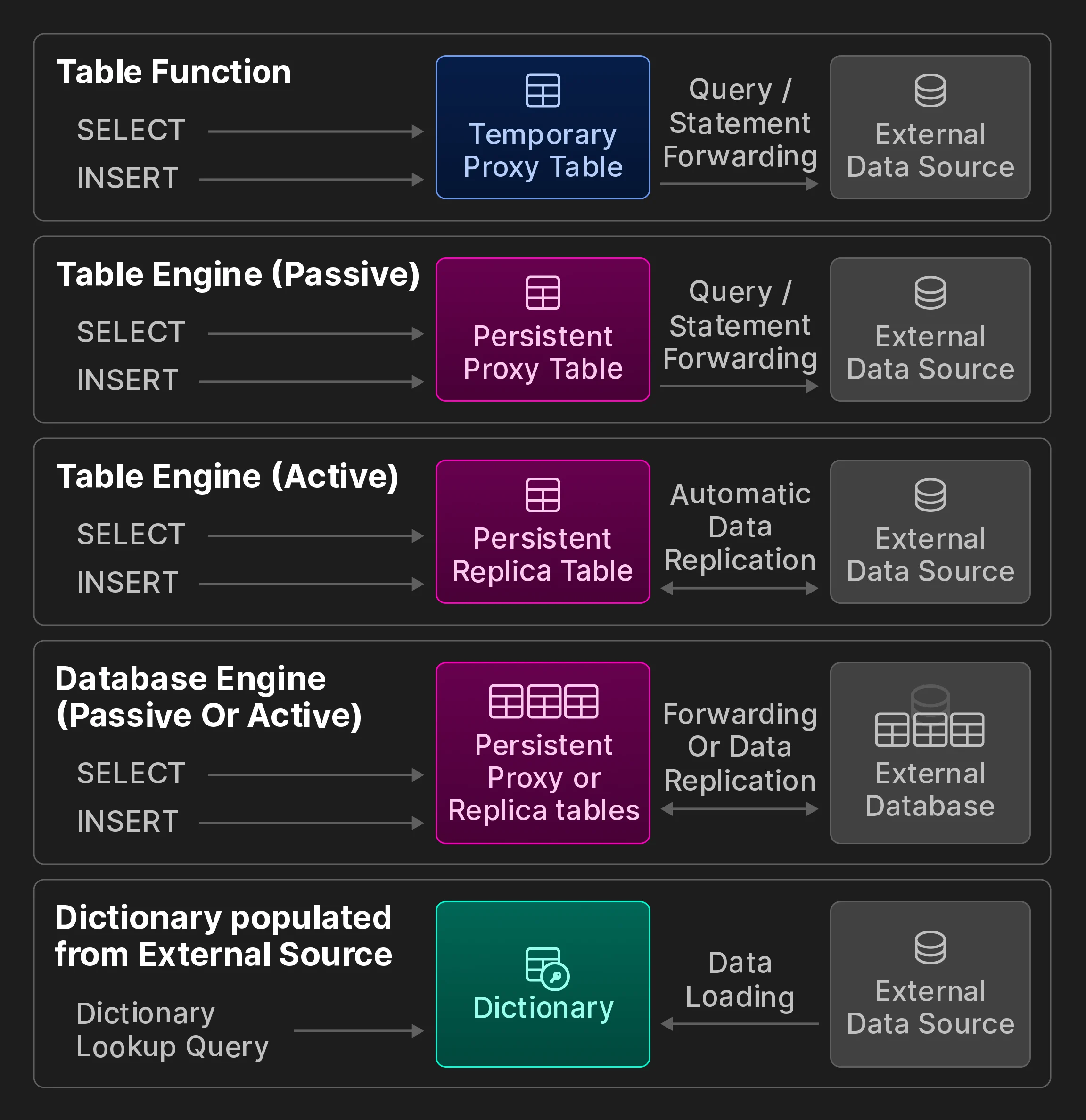
6 機能としてのパフォーマンス
6.1 組み込みの性能分析ツール
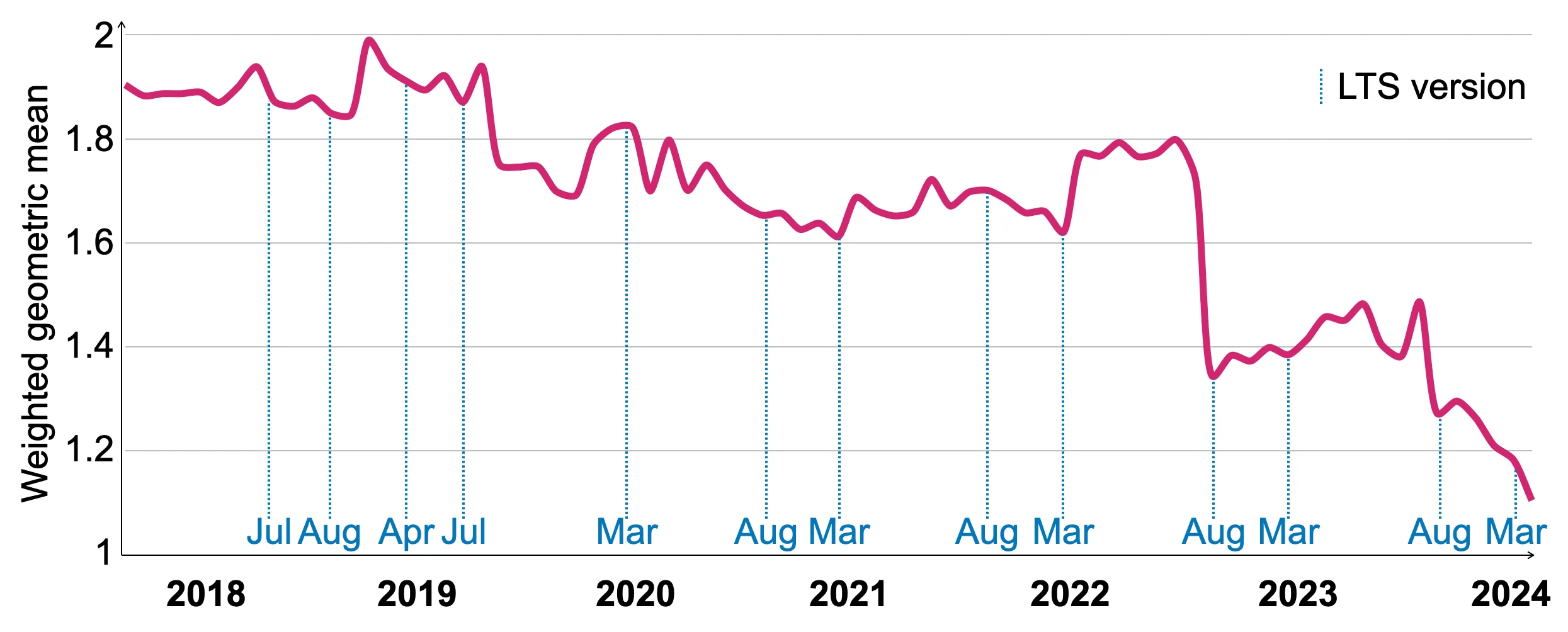
6.2 ベンチマーク
6.2.1 非正規化テーブル
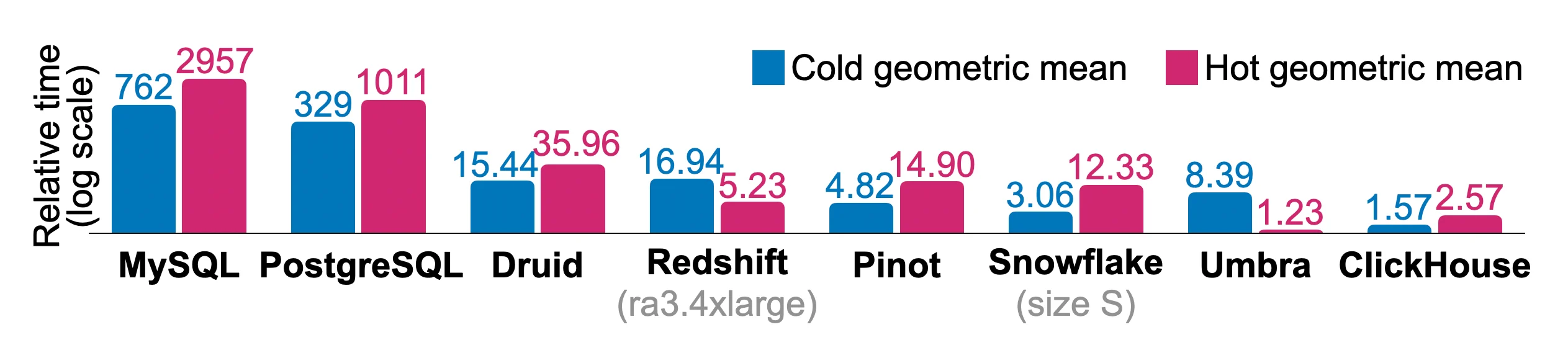
6.2.2 正規化テーブル

8 結論と展望
謝辞
SELECT * FROM system.contributors を実行すると、ClickHouse に貢献した 1994 人の名前が返されます。ClickHouse Inc. のエンジニアリングチームの皆様、そして ClickHouse のすばらしいオープンソースコミュニティの皆様が、このデータベースの構築に注いでくださった多大な努力と献身に、心より感謝いたします。
リファレンス
- 1 Daniel Abadi、Peter Boncz、Stavros Harizopoulos、Stratos Idreaos、Samuel Madden. 2013. The Design and Implementation of Modern Column-Oriented Database Systems. https://doi.org/10.1561/9781601987556
- 2 Daniel Abadi、Samuel Madden、Miguel Ferreira。2006年。Integrating Compression and Execution in Column-Oriented Database Systems. Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘06)、671–682。https://doi.org/10.1145/1142473.1142548
- 3 Anastassia Ailamaki、David J. DeWitt、Mark D. Hill、Marios Skounakis. 2001. Weaving Relations for Cache Performance. In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB ‘01). Morgan Kaufmann Publishers Inc.、San Francisco、CA、USA、169–180.
- 4 Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian, and Doug Terry. 2022. Amazon Redshift Re-Invented. In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- 5 Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin, and Matei Zaharia. 2022. Photon: A Fast Query Engine for Lakehouse Systems (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- 6 Philip A. Bernstein、Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- 7 Spyros Blanas、Yinan Li、Jignesh M. Patel. 2011. Design and evaluation of main memory hash join algorithms for multi-core CPUs. Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD ‘11) 所収。Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- 8 Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- 9 Burton H. Bloom. 1970. Space/Time Trade-Ofs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- 10 Peter Boncz, Thomas Neumann, and Orri Erling. 2014. TPC-H Analyzed: Hidden Messages and Lessons Learned from an Infuential Benchmark. In Performance Characterization and Benchmarking. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- 11 Peter Boncz、Marcin Zukowski、および Niels Nes。2005年。MonetDB/X100: Hyper-Pipelining Query Execution。CIDRにて。
- 12 Martin Burtscher、Paruj Ratanaworabhan. 2007. High Throughput Compression of Double-Precision Floating-Point Data. In Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- 13 Jef Carpenter、Eben Hewitt. 2016. Cassandra: The Defnitive Guide (第2版) . O’Reilly Media, Inc.
- 14 Bernadette Charron-Bost、Fernando Pedone、and André Schiper (編) . 2010. Replication: Theory and Practice. Springer-Verlag.
- 15 chDB. 2024. chDB - 組み込み型のOLAP SQL Engine。2024-06-20に https://github.com/chdb-io/chdb から取得。
- 16 ClickHouse. 2024. ClickBench: 分析データベース向けベンチマーク. 2024-06-20に取得、https://github.com/ClickHouse/ClickBench
- 17 ClickHouse. 2024. ClickBench: 比較測定。2024-06-20取得、https://benchmark.clickhouse.com より
- 18 ClickHouse. 2024. ClickHouse Roadmap 2024 (GitHub). https://github.com/ClickHouse/ClickHouse/issues/58392 より2024-06-20取得
- 19 ClickHouse. 2024. ClickHouse Versions Benchmark. 2024-06-20に https://github.com/ClickHouse/ClickBench/tree/main/versions から取得。
- 20 ClickHouse. 2024. ClickHouse Versions Benchmark Results. https://benchmark.clickhouse.com/versions/ より2024-06-20取得
- 21 Andrew Crotty. 2022. MgBench. 2024-06-20に以下から取得:https://github.com/ andrewcrotty/mgbench
- 22 Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. 2016. The Snowfake Elastic Data Warehouse. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 215–226. https: //doi.org/10.1145/2882903.2903741
- 23 Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich, and Wolfgang Lehner. 2019. From a Comprehensive Experimental Survey to a Cost-Based Selection Strategy for Lightweight Integer Compression Algorithms. ACM Trans. Database Syst. 44, 3, Article 9 (2019), 46ページ. https://doi.org/10.1145/3323991
- 24 Philippe Dobbelaere and Kyumars Sheykh Esmaili. 2017. Kafka versus RabbitMQ: A Comparative Study of Two Industry Reference Publish/Subscribe Implementations: Industry Paper (DEBS ‘17). Association for Computing Machinery, New York, NY, USA, 227–238. https://doi.org/10.1145/3093742.3093908
- 25 LLVM ドキュメント。2024年。LLVM における自動ベクトル化。2024-06-20 に https://llvm.org/docs/Vectorizers.html から取得
- 26 Siying Dong、Andrew Kryczka、Yanqin Jin、Michael Stumm. 2021. RocksDB: Evolution of Development Priorities in a キー・バリュー Store Serving Large-scale Applications. ACM Transactions on Storage 17, 4, Article 26 (2021), 32 pages. https://doi.org/10.1145/3483840
- 27 Markus Dreseler, Martin Boissier, Tilmann Rabl, and Matthias Ufacker. 2020. Quantifying TPC-H choke points and their optimizations. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- 28 Ted Dunning. 2021. The t-digest: 分布の効率的な推定. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- 29 Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, and Hasso Plattner. 2016. Footprint Reduction and Uniqueness Enforcement with Hash Indices in SAP HANA. In Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- 30 Philippe Flajolet、Eric Fusy、Olivier Gandouet、Frederic Meunier。2007年。HyperLogLog: ほぼ最適なカーディナリティ推定アルゴリズムの解析。『AofA: Analysis of Algorithms, Vol. DMTCS Proceedings vol. AH, 2007 Conference on Analysis of Algorithms (AofA 07)』所収。Discrete Mathematics and Theoretical Computer Science、137–156。https://doi.org/10.46298/dmtcs.3545
- 31 Hector Garcia-Molina, Jefrey D. Ullman, and Jennifer Widom. 2009. Database Systems - The Complete Book (2. Ed.).
- 32 Pawan Goyal, Harrick M. Vin, and Haichen Chen. 1996. Start-time fair queueing: a scheduling algorithm for integrated services packet switching networks. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- 33 Goetz Graefe. 1993. Query Evaluation Techniques for Large Databases. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- 34 Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, and Ravi Aringunram. 2018. Pinot: 5億3,000万人のユーザー向けリアルタイムOLAP. In Proceedings of the 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD ‘18). Association for Computing Machinery, New York, NY, USA, 583–594. https://doi.org/10.1145/3183713.3190661
- 35 ISO/IEC 9075-9:2001 2001. 情報技術 — データベース言語 — SQL — 第9部:外部データの管理 (SQL/MED) 。規格。国際標準化機構。
- 36 Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica, and Matei Zaharia. 2023. Analyzing and Comparing Lakehouse Storage Systems. CIDR.
- 37 Project Jupyter. 2024. Jupyter Notebooks. 2024-06-20閲覧、https: //jupyter.org/
- 38 Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. 2018. Everything You Always Wanted to Know about Compiled and Vectorized Queries but Were Afraid to Ask. Proc. VLDB Endow. 11, 13 (sep 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- 39 Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, and Pradeep Dubey. 2010. FAST: 最新のCPUおよびGPU向けの、高速でアーキテクチャ特性を考慮した木探索. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD ‘10). Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- 40 Donald E. Knuth. 1973. The Art of Computer Programming, Volume III: Sorting and Searching. Addison-Wesley.
- 41 André Kohn、Viktor Leis、Thomas Neumann. 2018. Adaptive Execution of Compiled Queries. In 2018 IEEE 34th International Conference on Data Engineering (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- 42 Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (aug 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- 43 Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, and Alfons Kemper. 2016. Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation. 『Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16)』所収. Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- 44 Viktor Leis、Peter Boncz、Alfons Kemper、および Thomas Neumann. 2014. Morseldriven parallelism: a NUMA-aware query evaluation framework for the manycore age. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- 45 Viktor Leis, Alfons Kemper, and Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. In 2013 IEEE 29th International Conference on Data Engineering (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- 46 Chunwei Liu、Anna Pavlenko、Matteo Interlandi、Brandon Haynes. 2023. A Deep Dive into Common Open Formats for Analytical DBMSs. 16, 11 (7月 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- 47 Zhenghua Lyu、Huan Hubert Zhang、Gang Xiong、Gang Guo、Haozhou Wang、Jinbao Chen、Asim Praveen、Yu Yang、Xiaoming Gao、Alexandra Wang、Wen Lin、Ashwin Agrawal、Junfeng Yang、Hao Wu、Xiaoliang Li、Feng Guo、Jiang Wu、Jesse Zhang、Venkatesh Raghavan。2021年。Greenplum: トランザクションおよび分析ワークロード向けのハイブリッドデータベース (SIGMOD ‘21) 。Association for Computing Machinery、New York, NY, USA、2530–2542。 https: //doi.org/10.1145/3448016.3457562
- 48 Roger MacNicol and Blaine French. 2004. Sybase IQ Multiplex - 分析向けに設計された。In Proceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30 (Toronto, Canada) (VLDB ‘04). VLDB Endowment, 1227–1230.
- 49 Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, and Jef Shute. 2020. Dremel: WebスケールでのインタラクティブSQL分析の10年. Proc. VLDB Endow. 13, 12 (aug 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- 50 Microsoft. 2024. Kusto Query Language. https: //github.com/microsoft/Kusto-Query-Language より2024-06-20取得
- 51 Guido Moerkotte. 1998. Small Materialized Aggregates: データウェアハウジングのための軽量な索引構造. In 第24回 International Conference on Very Large Data Bases (VLDB ‘98) 論文集. 476–487.
- 52 Jalal Mostafa、Sara Wehbi、Suren Chilingaryan、Andreas Kopmann。2022。SciTS: A Benchmark for Time-Series Databases in Scientifc Experiments and Industrial Internet of Things。Proceedings of the 34th International Conference on Scientifc and Statistical Database Management (SSDBM ‘22) 所収。Article 12。 https: //doi.org/10.1145/3538712.3538723
- 53 Thomas Neumann. 2011. efficiently Compiling efficient Query Plans for Modern Hardware. Proc. VLDB Endow. 4, 9 (jun 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- 54 Thomas Neumann and Michael J. Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. 10th Conference on Innovative Data Systems Research, CIDR 2020, Amsterdam, The Netherlands, January 12-15, 2020, Online Proceedings 所収. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- 55 Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD ‘15). Association for Computing Machinery, New York, NY, USA, 677–689. https://doi.org/10.1145/2723372. 2749436
- 56 GitHub 上の LevelDB。2024年。LevelDB。 https://github. com/google/leveldb から 2024-06-20 に取得
- 57 Patrick O’Neil, Elizabeth O’Neil, Xuedong Chen, and Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. In Performance Evaluation and Benchmarking. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- 58 Patrick E. O’Neil、Edward Y. C. Cheng、Dieter Gawlick、および Elizabeth J. O’Neil。1996。The log-structured Merge-Tree (LSM-tree)。Acta Informatica 33 (1996) 、351–385。https://doi.org/10.1007/s002360050048
- 59 Diego Ongaro、John Ousterhout. 2014. In Search of an Understandable Consensus Algorithm. In Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference (USENIX ATC’14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- 60 Patrick O’Neil、Edward Cheng、Dieter Gawlick、Elizabeth O’Neil。1996年。The Log-Structured Merge-Tree (LSM-Tree)。Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- 61 Pandas. 2024. Pandas Dataframes. https://pandas. pydata.org/ より 2024-06-20 取得
- 62 Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, および Biswapesh Chattopadhyay. 2022. Velox: Meta’s Unified Execution Engine. Proc. VLDB Endow. 15, 12 (2022年8月), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- 63 Tuomas Pelkonen、Scott Franklin、Justin Teller、Paul Cavallaro、Qi Huang、Justin Meza、Kaushik Veeraraghavan. 2015. Gorilla: A Fast, Scalable, in-Memory Time Series Database. Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- 64 Orestis Polychroniou, Arun Raghavan, and Kenneth A. Ross. 2015. Rethinking SIMD Vectorization for In-Memory Databases. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- 65 PostgreSQL。2024年。PostgreSQL - 外部データラッパー。https://wiki.postgresql.org/wiki/Foreign_data_wrappers より2024-06-20取得
- 66 Mark Raasveldt、Pedro Holanda、Tim Gubner、Hannes Mühleisen. 2018. Fair Benchmarking Considered difficult: Common Pitfalls In Database Performance Testing. In Proceedings of the Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). 論文2、全6ページ。 https://doi.org/10.1145/3209950.3209955
- 67 Mark Raasveldt、Hannes Mühleisen. 2019. DuckDB: An Embeddable Analytical Database (SIGMOD ‘19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869.3320212
- 68 Jun Rao and Kenneth A. Ross. 1999. Cache Conscious Indexing for Decision-Support in Main Memory. Proceedings of the 25th International Conference on Very Large Data Bases (VLDB ‘99), San Francisco, CA, USA, 78–89.
- 69 Navin C. Sabharwal and Piyush Kant Pandey. 2020. Working with Prometheus Query Language (PromQL). 『Monitoring Microservices and Containerized Applications』所収. https://doi.org/10.1007/978-1-4842-6216-0_5
- 70 Todd W. Schneider. 2022. New York City Taxi and For-Hire Vehicle Data. 2024-06-20に https://github.com/toddwschneider/nyc-taxi-data から取得
- 71 Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. 2005. C-Store: A Column-Oriented DBMS. In Proceedings of the 31st International Conference on Very Large Data Bases (VLDB ‘05). 553–564.
- 72 Teradata. 2024. Teradata Database. 2024-06-20に取得。https://www. teradata.com/resources/datasheets/teradata-database
- 73 Frederik Transier. 2010. インメモリ・テキスト検索エンジンのためのアルゴリズムとデータ構造. 博士論文. https://doi.org/10.5445/IR/1000015824
- 74 Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, and Manuel Then. 2018. Get Real: How Benchmarks Fail to Represent the Real World. In Proceedings of the Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). 論文番号1、全6ページ。 https://doi.org/10.1145/3209950.3209952
- 75 LZ4 ウェブサイト。2024年。LZ4。https://lz4.org/ (2024-06-20 取得)
- 76 PRQLウェブサイト。2024年。PRQL。2024-06-20に https://prql-lang.org より取得。77 Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000. The Implementation and Performance of Compressed Databases. SIGMOD Rec.
- 29, 3 (2000年9月), 55–67. https://doi.org/10.1145/362084.362137 78 Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. Druid: A Real-Time Analytical Data Store. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- 79 Tianqi Zheng, Zhibin Zhang, and Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- 80 Jingren Zhou and Kenneth A. Ross. 2002. SIMD 命令を用いたデータベース操作の実装. In 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘02) 論文集. 145–156. https://doi.org/10. 1145/564691.564709
- 81 Marcin Zukowski, Sandor Heman, Niels Nes, Peter Boncz. 2006. Super-Scalar RAM-CPU Cache Compression. 『Proceedings of the 22nd International Conference on Data Engineering (ICDE ‘06)』所収. 59. https://doi.org/10.1109/ICDE. 2006.150