摘要
1 引言
- 海量数据集与高摄取速率。在网站分析、金融、电子商务等行业,许多数据驱动型应用的特点是数据量巨大且持续增长。为了处理海量数据集,分析型数据库不仅要提供高效的索引和压缩策略,还必须支持将数据分布到多个节点上 (横向扩展) ,因为单台服务器的存储容量通常仅限于数十 TB。此外,相比历史数据,较新的数据往往对实时洞察更有价值。因此,分析型数据库必须能够持续以高吞吐率或突发方式摄取新数据,同时持续对历史数据进行“降级处理” (例如聚合、归档) ,而不拖慢并行报表查询。
- 大量并发查询且要求低延迟。查询通常可分为即席查询 (例如探索性数据分析) 和重复性查询 (例如周期性的仪表板查询) 。使用场景的交互性越强,对查询延迟的要求就越高,这也给查询优化和执行带来了挑战。重复性查询还提供了根据工作负载调整数据库物理布局的机会。因此,数据库应提供剪枝技术,以优化高频查询。此外,根据查询优先级,即使有大量查询同时运行,数据库也必须能够对 CPU、内存、磁盘和网络 I/O 等共享系统资源提供公平或优先的访问。
- 多样化的数据存储、存储位置和格式。为了与现有数据架构集成,现代分析型数据库应具备高度开放性,能够在任何系统、位置或格式中读写外部数据。
- 便捷的查询语言,并支持性能内部信息分析。OLAP 数据库在实际使用中还面临一些额外的“软性”要求。例如,用户通常更希望通过富有表现力的 SQL 方言与数据库交互,而不是使用小众编程语言;这种 SQL 方言还应支持嵌套数据类型,以及丰富的常规函数、聚合函数和窗口函数。分析型数据库还应提供成熟的工具,用于分析系统或单个查询的性能内部信息。
- 工业级稳健性与灵活部署。由于通用硬件并不可靠,数据库必须提供数据复制,以增强节点故障情况下的稳健性。此外,数据库应能运行在各种硬件上,从老旧笔记本到高性能服务器皆可。最后,为了避免基于 JVM 的程序中的垃圾回收开销,并实现裸机性能 (例如 SIMD) ,数据库最好以面向目标平台的原生二进制形式部署。

2 架构
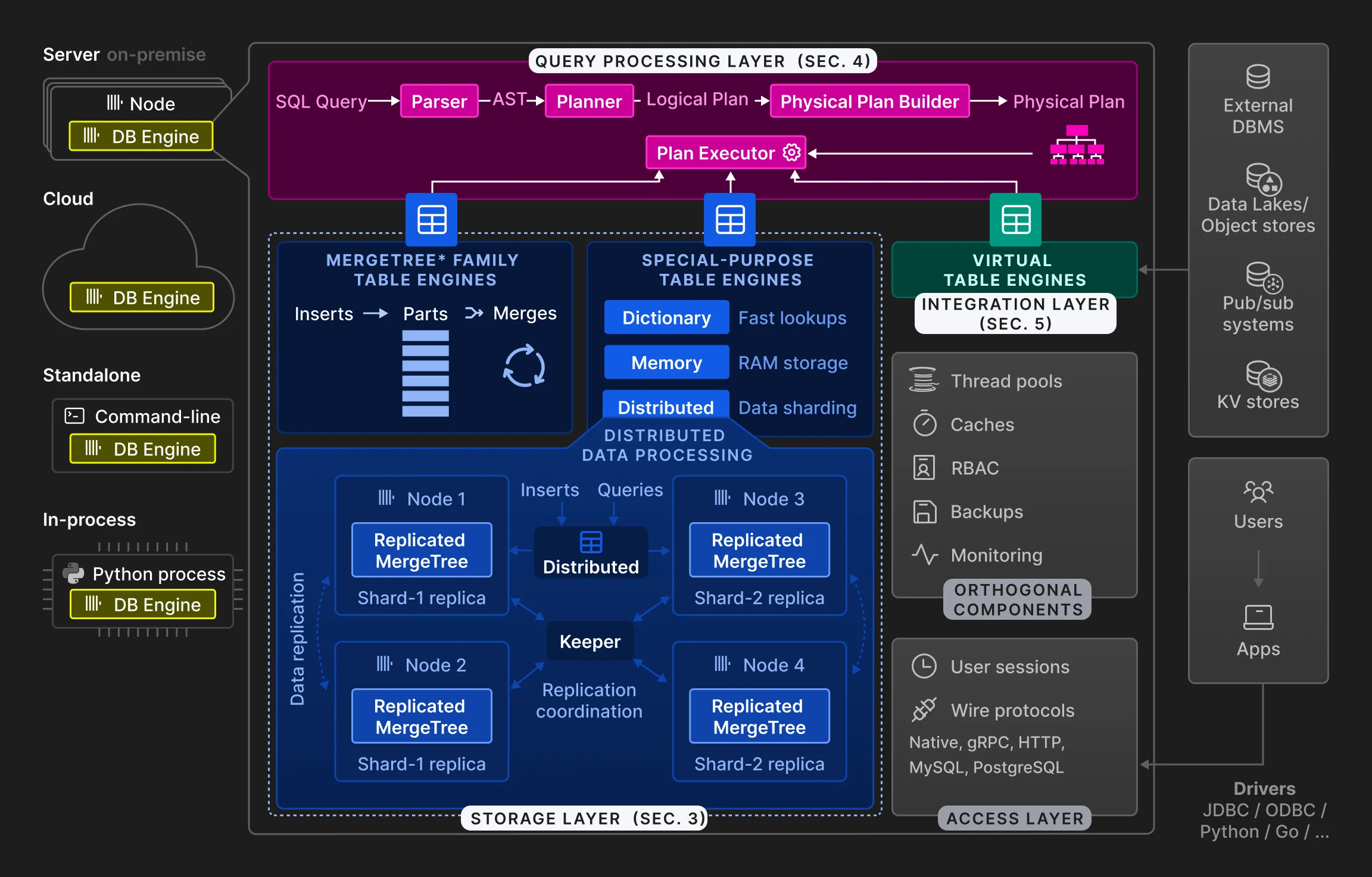
3 存储层
本节介绍作为 ClickHouse 原生存储格式的 MergeTree* 表引擎。我们将说明它们在磁盘上的表示方式,并讨论 ClickHouse 中三种数据剪枝技术。随后,我们将介绍在不影响并发 insert 的情况下持续转换数据的合并策略。最后,我们将说明更新和删除的实现方式,以及数据去重、数据复制和 ACID 合规性。3.1 磁盘格式
MergeTree* 表引擎中的每个表都组织为一组不可变的表分片。每当一批行被插入到表中时,就会创建一个分片。分片是自包含的,也就是说,它们包含了解释其内容所需的全部元数据,无需再到中央元数据目录中额外查找。为了将每个表的分片数量控制在较低水平,后台 merge job 会定期将多个较小的分片合并成一个较大的分片,直到达到可配置的分片 大小 (默认 150 GB) 。由于分片会按表的主键列排序 (见第 3.2) 节) ,因此合并时会使用高效的 k 路归并排序 [40]。源分片会被标记为非活动状态,并在其引用计数降为零时最终删除,也就是不再有查询从中读取数据时。 行可以通过两种模式插入:在同步插入模式下,每条 INSERT 语句都会创建一个新的分片,并将其追加到表中。为了尽量降低 merge 的开销,通常建议数据库客户端批量插入元组,例如一次插入 20,000 行。不过,如果数据需要进行实时分析,那么由客户端侧批处理带来的延迟往往是不可接受的。例如,可观测性场景通常涉及数千个监控 agent 持续发送少量事件和指标数据。在这种场景下,可以使用异步插入模式:ClickHouse 会将发往同一张表的多个传入 INSERT 中的行缓存在一起,只有当缓冲区大小超过可配置阈值或发生超时后,才会创建新的分片。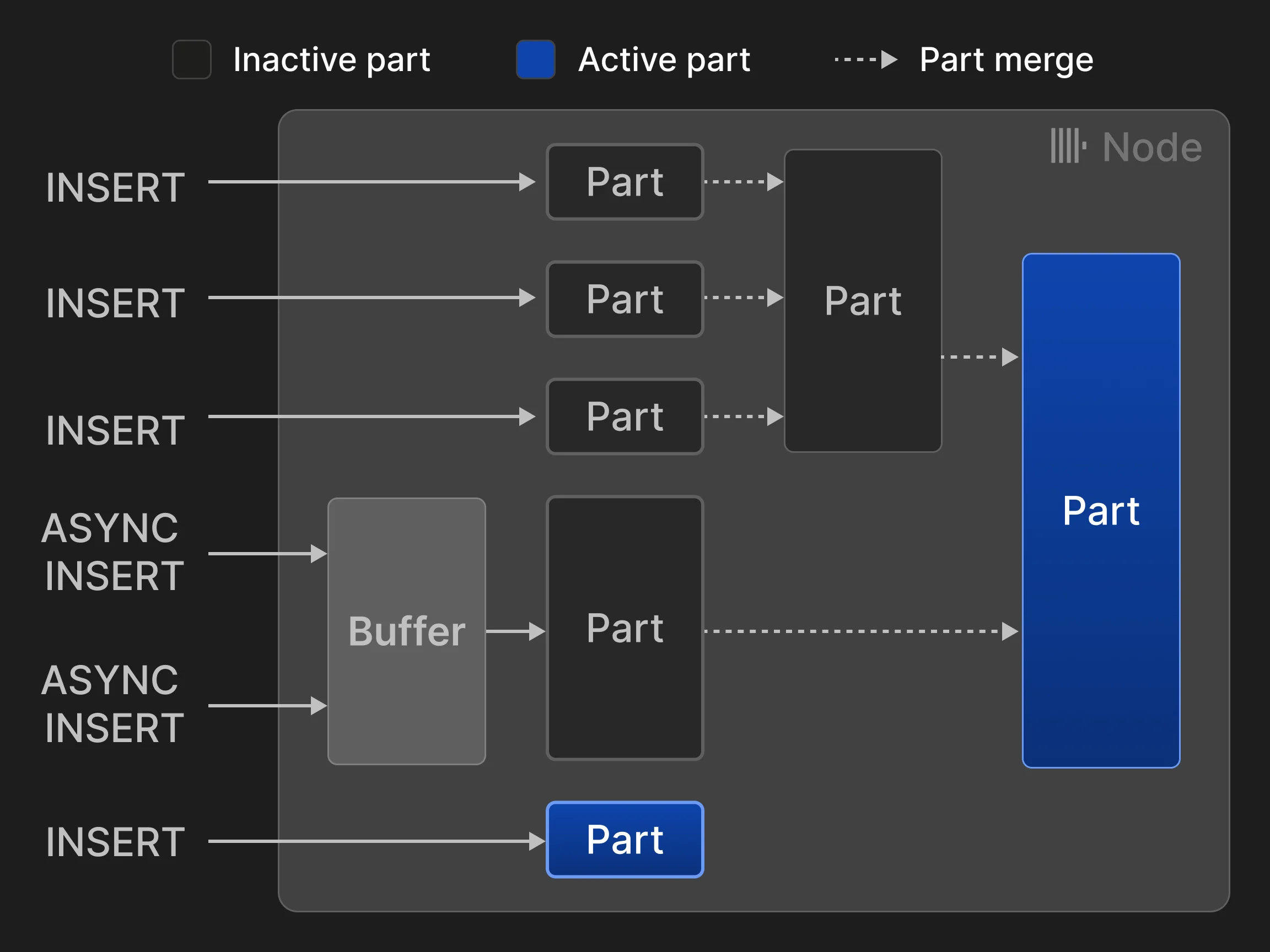
3.2 数据裁剪
在大多数使用场景中,仅为回答单个查询而扫描 PB 级数据,速度太慢且成本太高。ClickHouse 支持三种数据裁剪技术,可在搜索时跳过绝大多数行,从而显著提升查询速度。 首先,用户可以为表定义一个主键索引。主键列决定了每个分片内行的排序顺序,也就是说,该索引是局部聚簇的。此外,对于每个分片,ClickHouse 还会存储从每个粒度首行的主键列值到该粒度 id 的映射,即该索引是稀疏的 [31]。由此形成的数据结构通常足够小,能够完全驻留在内存中,例如,仅需 1000 个条目即可为 810 万行建立索引。主键的主要作用是针对经常用于过滤的列,使用二分查找而非顺序扫描来评估等值和范围谓词 (第 4.4) 节) 。此外,这种局部排序还可用于 分片 merge 和查询优化,例如基于排序的 aggregation,或者当主键列构成排序列的前缀时,从物理执行计划中移除排序算子。 图 4 展示了页面展示统计表中基于列 EventTime 的主键索引。查询中满足范围谓词的粒度可以通过对主键索引进行二分查找来定位,而无需顺序扫描 EventTime。
3.3 合并时数据转换
商业智能和可观测性场景通常需要处理持续高速产生或突发产生的数据。此外,与历史数据相比,最近生成的数据通常对获取有意义的实时洞察更有价值。这类场景要求数据库在维持高数据摄取速率的同时,通过聚合或数据老化等技术持续减少历史数据量。ClickHouse 允许通过不同的合并策略,对现有数据持续进行增量转换。合并时数据转换不会影响 INSERT 语句的性能,但无法保证表中绝不会包含不需要的值 (例如过期或未聚合的值) 。如有必要,可以通过在 SELECT 语句中指定关键字 FINAL,在查询时应用所有合并时转换。 替换合并仅保留元组中最近插入的版本,该版本根据其所在分片的创建时间戳确定,较旧的版本会被删除。如果元组具有相同的主键列值,则视为等价。为了显式控制保留哪个元组,也可以指定一个特殊的版本列进行比较。替换合并通常用作合并时更新机制 (通常适用于更新频繁的场景) ,或作为插入时数据去重 (第 3.5) 节) 的替代方案。 聚合合并会将具有相同主键列值的行折叠为一条聚合后的行。非主键列必须是保存汇总值的部分聚合状态。两个部分聚合状态 (例如 avg() 的 sum 和 count) 会合并成一个新的部分聚合状态。聚合合并通常用于 materialized view,而不是普通表。materialized view 基于针对源表的转换查询进行填充。与其他数据库不同,ClickHouse 不会定期用源表的全部内容刷新 materialized view。相反,当新的分片 插入源表时,materialized view 会根据转换查询的结果进行增量更新。 图 5 展示了一个定义在页面展示统计表上的 materialized view。对于插入源表的新分片,转换查询会按区域分组计算最大延迟和平均延迟,并将结果插入 materialized view。带有 -State 扩展的聚合函数 avg() 和 max() 返回的是部分聚合状态,而不是实际结果。为该 materialized view 定义的聚合合并会持续合并不同分片中的部分聚合状态。为了获得最终结果,用户可使用带有 -Merge 扩展的 avg() 和 max()) 对 materialized view 中的部分聚合状态进行合并。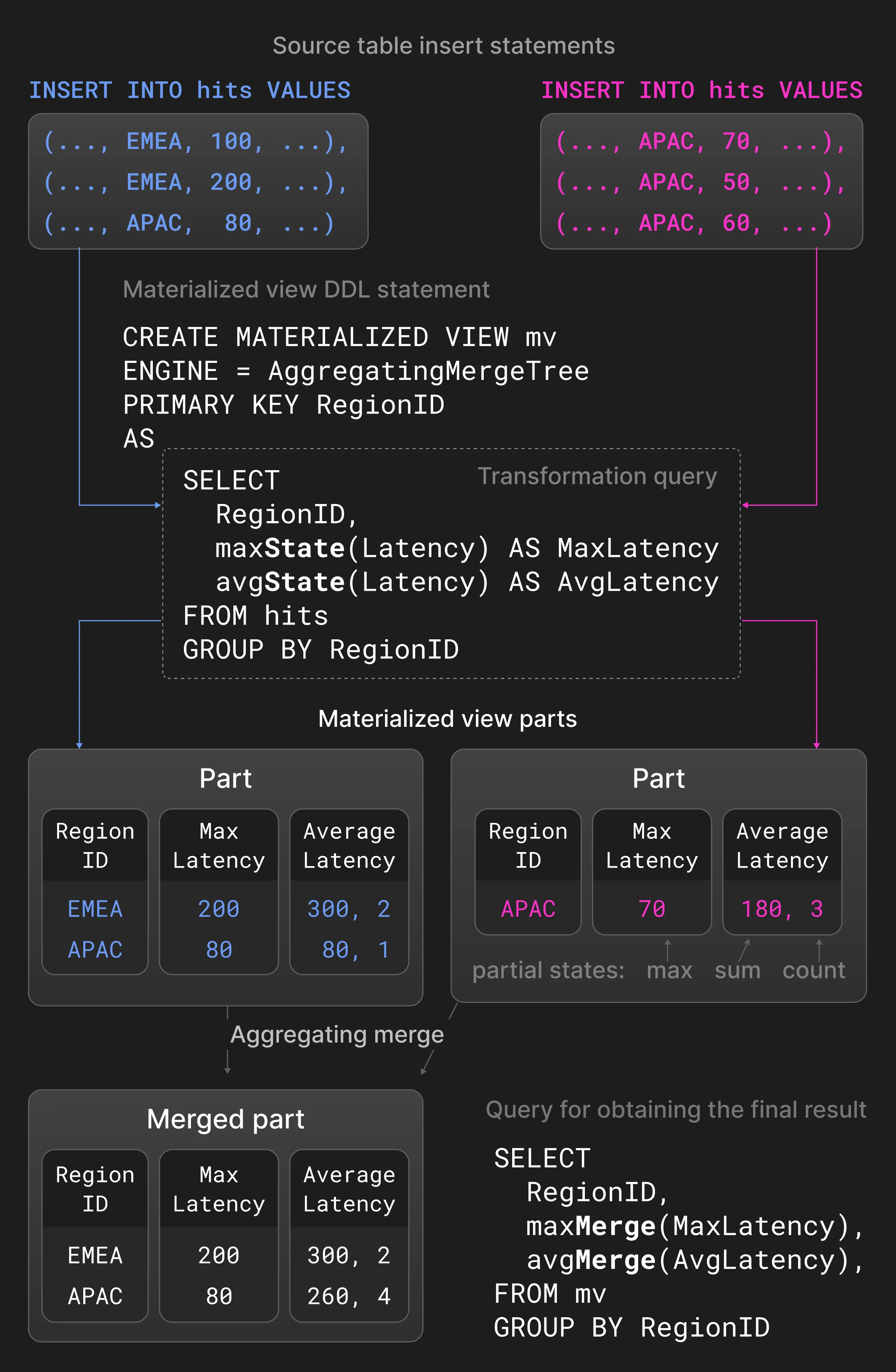
3.4 更新与删除
MergeTree* 表引擎的设计偏向仅追加型工作负载,但某些场景仍需要偶尔修改现有数据,例如满足合规要求。更新或删除数据有两种方式,这两种方式都不会阻塞并行插入。 变更会原地重写表中的所有分片。为避免表 (删除) 或列 (更新) 的大小暂时翻倍,该操作是非原子的,也就是说,并行的 SELECT 语句可能会读到已变更和未变更的分片。变更可保证在操作结束时数据已被物理修改。删除变更的开销仍然较高,因为它们会重写所有分片中的所有列。 作为替代方案,轻量级删除只会更新内部 bitmap 列,用于标记某一行是否已删除。ClickHouse 会在 SELECT 查询中额外附加针对 bitmap 列的过滤器,从结果中排除已删除的行。已删除的行只会在未来某个未指定时间通过常规 merge 被物理移除。视列数而定,轻量级删除可能比变更快得多,但代价是 SELECT 会变慢。 同一张表上的更新和删除操作通常应尽量少做,并串行执行,以避免逻辑冲突。3.5 幂等插入
实践中经常遇到的一个问题是:客户端在将数据发送到服务器插入表之后,如果发生连接超时,应该如何处理。在这种情况下,客户端很难判断数据究竟是否已经成功插入。传统的解决办法是客户端将数据重新发送到服务器,并依靠主键或唯一约束来拒绝重复插入。数据库会利用基于二叉树的索引结构 [39, [68]](#page-13-16)、基数树 [45] 或哈希表 [29] 快速完成所需的点查找。由于这些数据结构会为每个元组建立索引,因此对于大型数据集和高摄取速率来说,它们在空间和更新方面的开销会高得难以接受。 ClickHouse 提供了一种更轻量的替代方案,其依据是每次插入最终都会创建一个分片。更具体地说,服务器会维护最近插入的 N 个分片 (例如 N=100) 的哈希值,并忽略对哈希值已知的分片 的重复插入。非复制表和复制表的哈希值分别存储在本地和 Keeper 中。因此,插入就成为幂等操作,也就是说,客户端在超时后只需重新发送同一批次的行,并假定服务器会负责去重。为了更精细地控制去重过程,客户端还可以选择提供一个插入标记,作为分片 哈希使用。虽然基于哈希的去重会带来对新行进行哈希计算的额外开销,但存储和比较哈希的成本可以忽略不计。3.6 数据复制
复制是实现高可用性 (容忍节点故障) 的前置条件,但也可用于负载均衡和零停机升级 [14]。在 ClickHouse 中,复制基于表状态这一概念:表状态由一组表分片 (第 3.1) 节) 以及表元数据 (如列名和类型) 构成。节点通过三类操作推进表状态:1. 插入会向状态中新增一个分片;2. 合并会向状态中新增一个分片,并从状态中删除现有分片;3. 变更和 DDL 语句则会根据具体操作新增分片、和/或删除分片、和/或修改表元数据。这些操作都在单个节点上本地执行,并作为一系列状态转换记录到全局复制日志中。 复制日志由一组通常包含三个 ClickHouse Keeper 进程的节点维护,这些进程使用 Raft 共识算法 [59],为 ClickHouse 节点集群提供分布式、容错的协调层。所有集群节点最初都指向复制日志中的同一位置。当节点执行本地插入、合并、变更和 DDL 语句时,复制日志会在所有其他节点上异步重放。因此,复制表仅提供最终一致性,也就是说,节点在向最新状态收敛的过程中,可能会暂时读取到旧的表状态。上述大多数操作也可以改为同步执行,直到达到法定数量的节点 (例如大多数节点或所有节点) 采用新状态为止。 举例来说,图 6 展示了一个由三个 ClickHouse 节点组成的集群中一张初始为空的复制表。节点 1 首先接收两条插入语句,并将其记录到存储在 Keeper 集群中的复制日志中 ( 1 2 ) 。接着,节点 2 通过拉取第一条日志条目来重放该条目 ( 3 ) ,并从节点 1 下载新的分片 ( 4 ) ,而节点 3 则重放两条日志条目 ( 3 4 5 6 ) 。最后,节点 3 将这两个分片 合并为一个新的分片,删除输入分片,并在复制日志中记录一条合并条目 ( 7 ) 。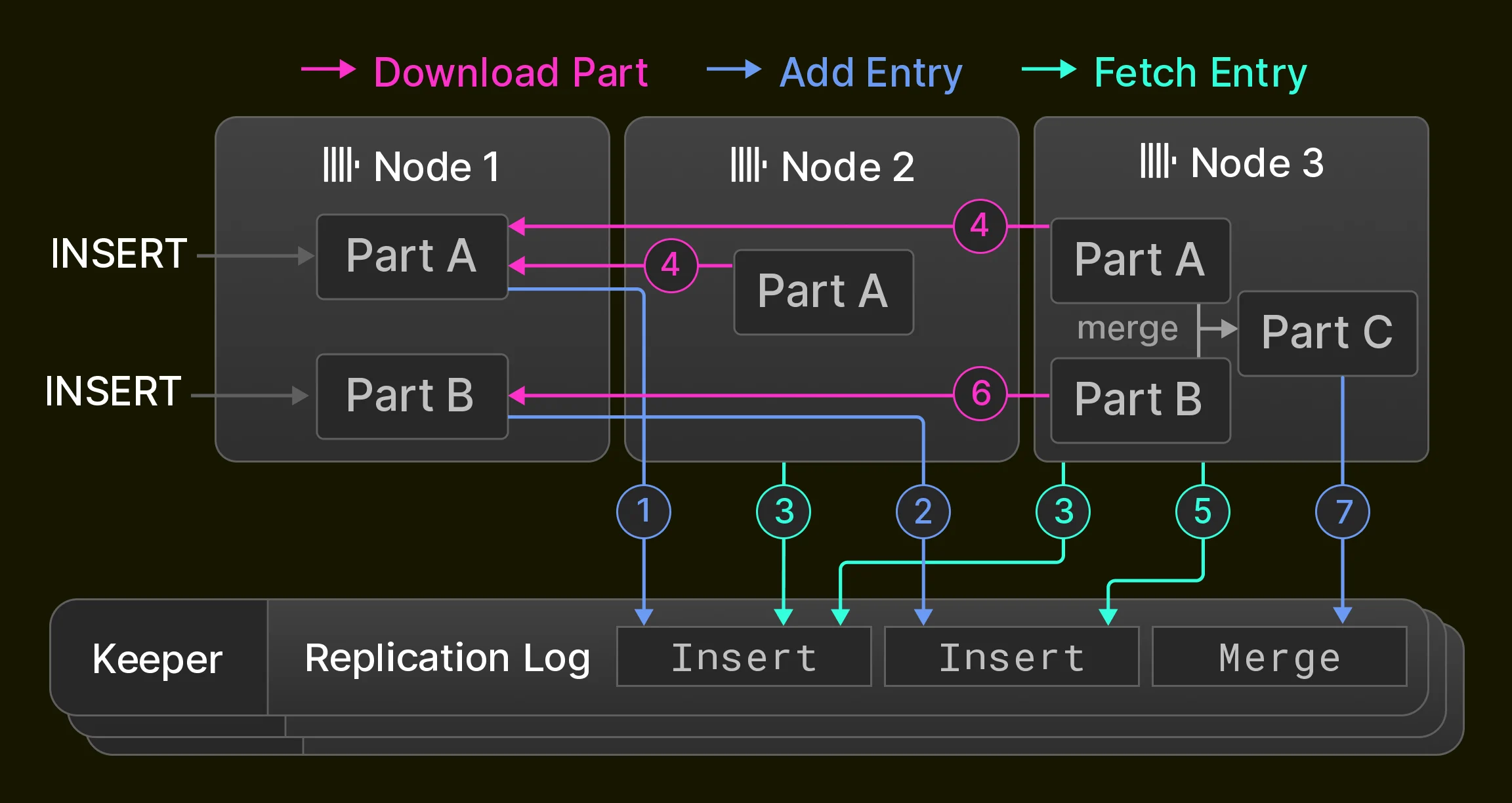
3.7 ACID 合规性
为了尽可能提升并发读写操作的性能,ClickHouse 会尽量避免使用闩锁。查询会基于在查询开始时创建的快照执行,该快照覆盖所有相关表中的全部分片。这可确保由并行 INSERT 或 merge 操作 (第 3.1) 节) 新插入的分片 不会参与本次执行。为防止分片 同时被修改或移除 (第 3.4) 节) ,在查询持续期间会增加所处理分片 的引用计数。从形式上讲,这对应于基于带版本分片 的 MVCC Variant [6] 实现的快照隔离。因此,这些语句通常并不符合 ACID,只有一种少见情况例外:在获取快照时发生的并发写入各自只影响单个分片。 在实际场景中,大多数 ClickHouse 写密集型决策类用例甚至可以容忍在断电时丢失少量新数据的风险。数据库正是利用了这一点,默认不会强制将新插入的分片 提交 (fsync) 到磁盘,从而允许内核对写入进行批次处理,但代价是放弃原子性。4 查询处理层
4.1 SIMD 并行化
4.2 多核并行化
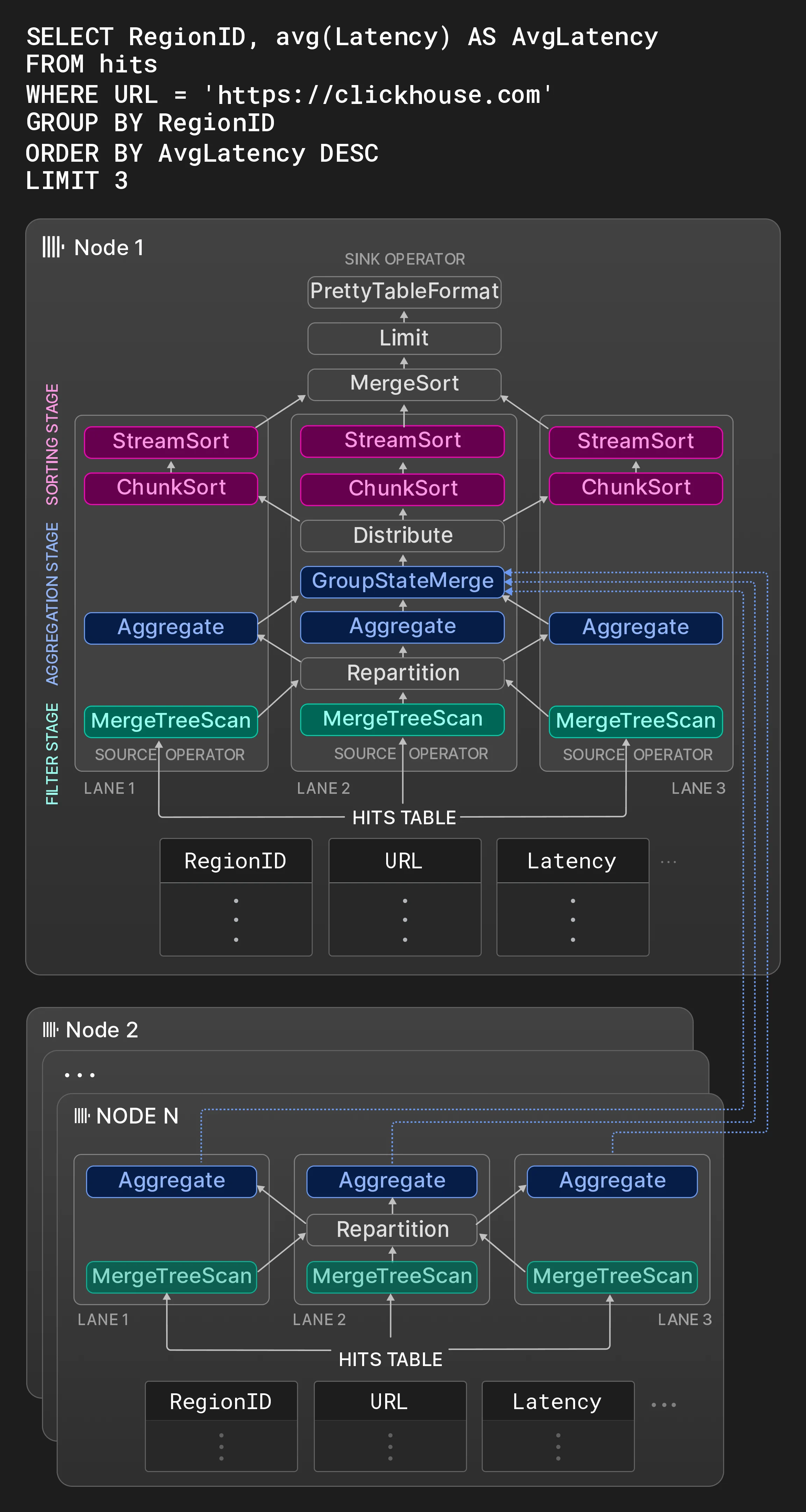
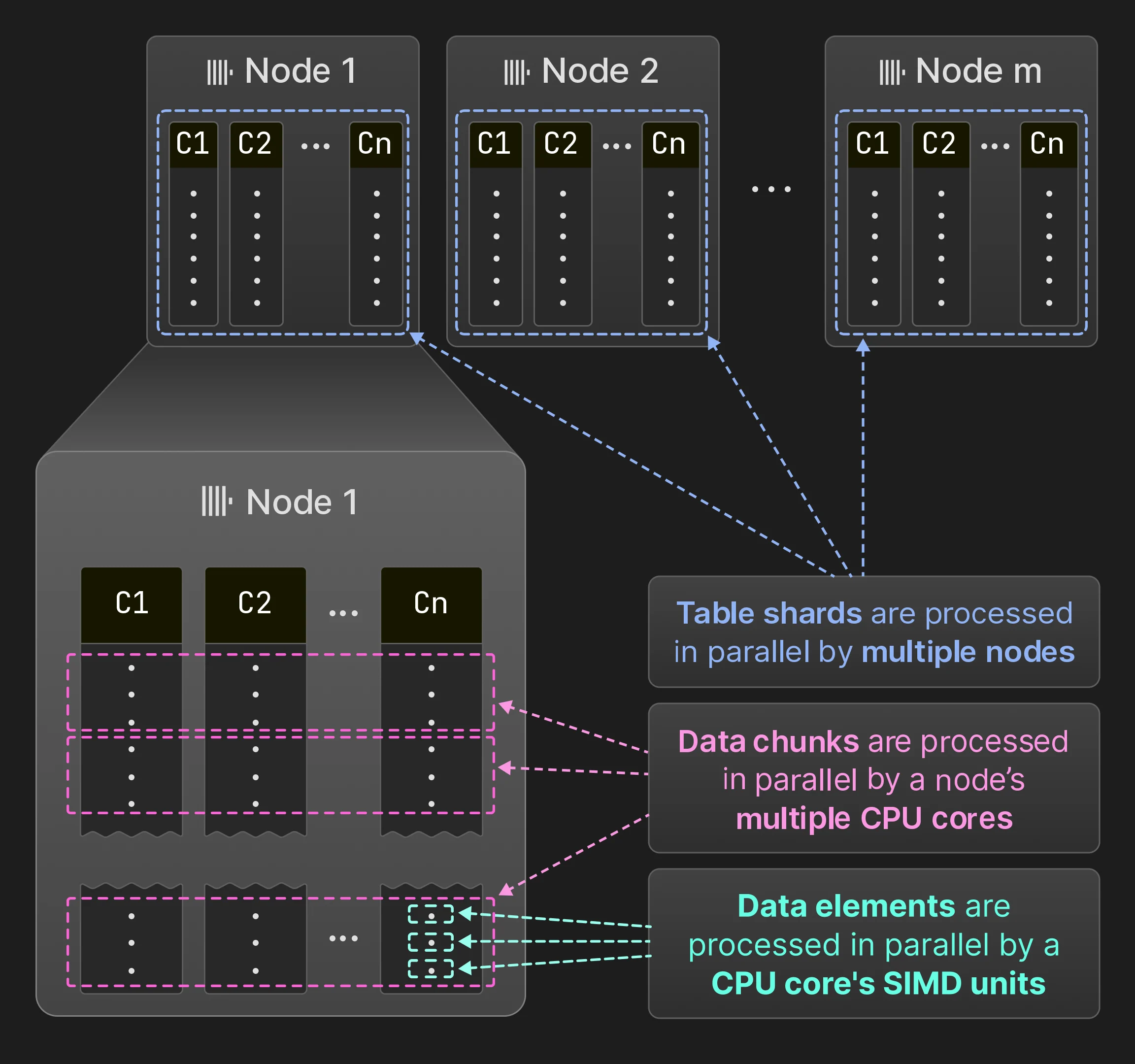
4.3 多节点并行化
4.4 整体性能优化
本节介绍在查询执行不同阶段采用的一些关键性能优化。 查询优化。第一类优化作用于根据查询 AST 得到的语义查询表示。这类优化包括常量折叠 (例如concat(lower('a'),upper('b')) 变为 'aB') 、从某些聚合函数中提取标量 (例如 sum(a*2) 变为 2 * sum(a)) 、公共子表达式消除,以及将等值过滤条件的析取改写为 IN 列表 (例如 x=c OR x=d 变为 x IN (c,d)) 。优化后的语义查询表示随后会转换为逻辑算子计划。在逻辑计划层面,还会进行过滤器下推,以及根据两者中哪一项预计代价更高来调整函数求值与排序步骤的顺序。最后,逻辑查询计划会转换为物理算子计划。该转换可以利用所涉表引擎的特性。例如,对于 MergeTree* 表引擎,如果 ORDER BY 列构成主键的前缀,就可以按磁盘上的顺序读取数据,并从计划中移除排序算子。此外,如果聚合中的分组列构成主键的前缀,ClickHouse 可以使用排序聚合 [33],即直接在预排序输入上对相同值的连续区间进行聚合。与哈希聚合相比,排序聚合的内存开销显著更低,而且在处理完一个连续区间后,就可以立即将聚合值传递给下一个算子。
查询编译。ClickHouse 使用基于 LLVM 的查询编译来动态融合相邻的计划算子 [38, [53]](#page-13-0)。例如,表达式 a * b + c + 1 可以合并为一个算子,而不是三个算子。除了表达式之外,ClickHouse 还会通过编译一次性计算多个聚合函数 (即用于 GROUP BY) ,以及处理包含多个排序键的排序操作。查询编译可减少虚调用次数,将数据保留在寄存器或 CPU 缓存中,并且由于需要执行的代码更少,也有助于分支预测器。此外,运行时编译还能带来丰富的优化,例如编译器中实现的逻辑优化和窥孔优化,并可使用本地可用的最快 CPU 指令。只有当同一个常规表达式、聚合表达式或排序表达式被不同查询执行超过某个可配置次数时,才会触发编译。编译后的查询算子会被缓存,并可供后续查询复用。[7]
主键索引求值。如果 WHERE 条件的合取范式中有一部分过滤子句构成主键列的前缀,ClickHouse 就会使用主键索引来计算该 WHERE 条件。主键索引会在按字典序排序的键值范围上自左向右进行分析。与主键列对应的过滤子句采用三值逻辑求值——对于该范围内的值,它们要么全为真,要么全为假,要么真假混合。在最后一种情况下,该范围会被拆分为子范围,并递归分析。对于过滤条件中的函数,还存在额外优化。首先,函数带有描述其单调性的特征,例如 toDayOfMonth(date) 在一个月内是分段单调的。借助这些单调性特征,可以推断函数在已排序输入键值范围上是否会产生有序结果。其次,某些函数可以计算给定函数结果的原像。这可用于将“对常量的比较 + 对键列调用函数”的形式,改写为直接将键列值与原像比较。例如,toYear(k) = 2024 可以替换为 k >= 2024-01-01 && k < 2025-01-01。
数据跳过。ClickHouse 会尝试利用第 3.2. 节介绍的数据结构,在查询运行时避免读取数据。此外,不同列上的过滤器会基于启发式规则和 (可选的) 列统计信息,按估计选择性从高到低的顺序依次求值。只有至少包含一条匹配行的数据块才会传递给下一个谓词。这样会随着谓词逐个执行,逐步减少需要读取的数据量和需要执行的计算量。只有在至少存在一个高选择性谓词时,才会应用这一优化;否则,与并行计算所有谓词相比,查询延迟反而会变差。
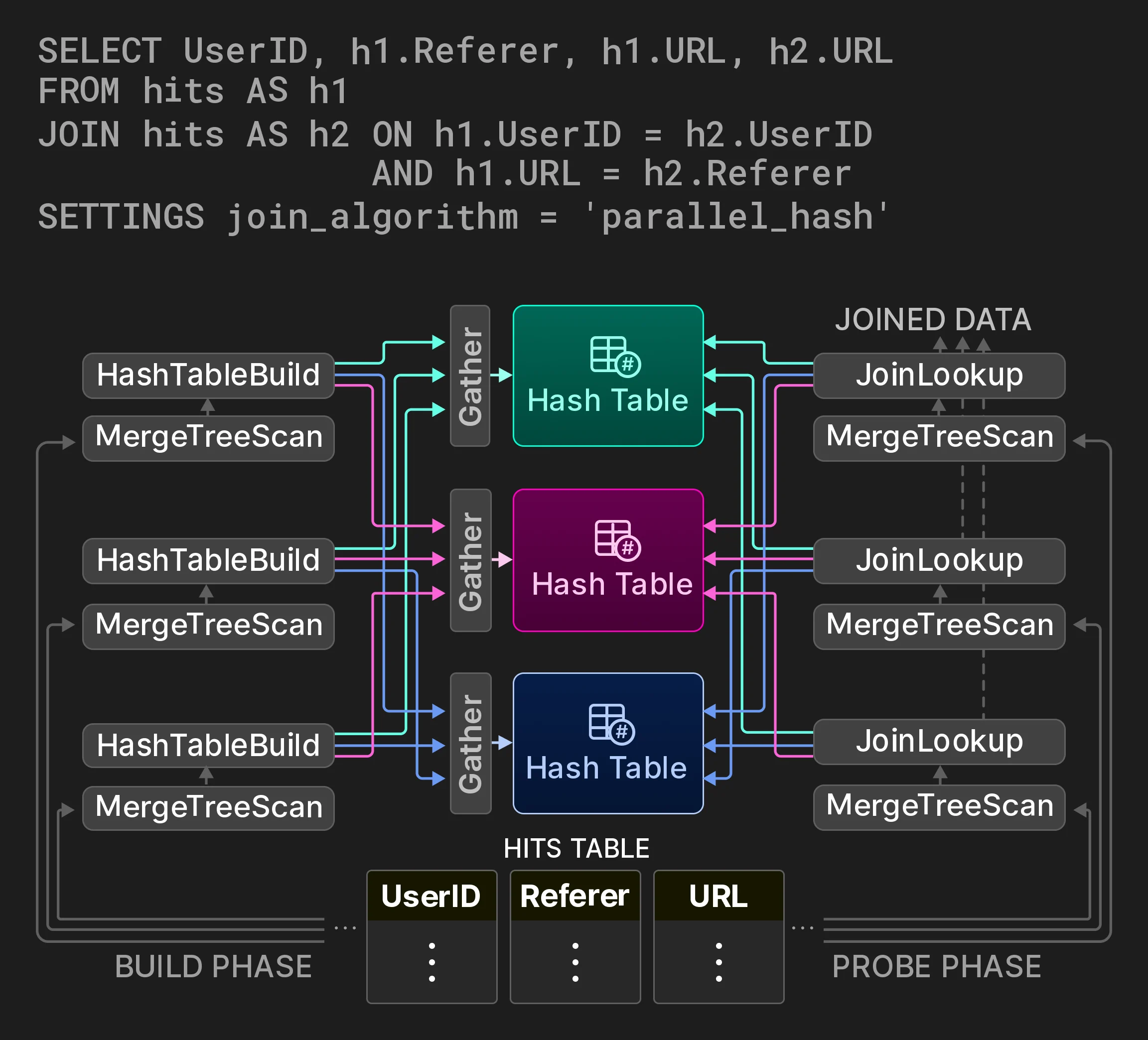
哈希表。哈希表是聚合和哈希 JOIN 的基础数据结构。选择合适的哈希表类型对性能至关重要。ClickHouse 以哈希函数、分配器、单元类型和扩容策略为可变点,从一个通用哈希表模板中实例化出多种哈希表 (截至 2024 年 3 月已超过 30 种) 。系统会根据分组列的数据类型、预估的哈希表基数以及其他因素,为每个查询算子分别选择最快的哈希表。针对哈希表还实现了以下优化:
- 采用包含 256 个子表的两级布局 (基于哈希值的第一个字节) ,以支持超大键集合,
- 字符串哈希表 [79] 使用四个子表,并针对不同字符串长度采用不同的哈希函数,
- 当键数量较少时,使用直接以键作为 bucket 索引 (即不做哈希) 的查找表,
- 当比较代价较高时 (例如字符串、AST) ,将哈希值嵌入 value 中,以加快冲突消解,
- 根据运行时统计预测的大小创建哈希表,以避免不必要的扩容,
- 将多个创建/销毁生命周期相同的小型哈希表分配到同一个内存 slab 上,
- 使用每个哈希映射和每个单元的版本计数器,快速清空哈希表以供复用,
- 使用 CPU 预取 (
__builtin_prefetch) 在对键进行哈希后加快值的读取。
4.5 工作负载隔离
ClickHouse 提供并发控制、内存使用限制和 I/O 调度功能,使用户能够将查询隔离到不同的工作负载类别中。通过为特定工作负载类别设置共享资源 (CPU 核心、DRAM、磁盘和网络 I/O) 的限制,可以确保这些查询不会影响其他关键业务查询。 并发控制可防止在线程并发查询数量较高的场景中出现线程过度订阅。更具体地说,每个查询的工作线程数会根据可用 CPU 核心数量的指定比例动态调整。 ClickHouse 会在 server、user 和 query 级别跟踪内存分配的字节大小,因此可以灵活设置内存使用限制。内存 overcommit 允许查询使用超出保障内存之外的额外空闲内存,同时保证其他查询的内存限制。此外,还可以限制 aggregation、sort 和 join 子句的内存使用;当超过内存限制时,会回退到外部算法。 最后,I/O 调度允许用户根据最大带宽、进行中的请求数以及策略 (例如 FIFO、SFC [32]) ,限制工作负载类别对本地和远程磁盘的访问。5 集成层
实时决策应用通常依赖于以高效、低延迟的方式访问分布在多个位置的数据。要让 OLAP 数据库能够使用外部数据,主要有两种方式。在基于推送的数据访问模式中,第三方组件充当数据库与外部数据存储之间的桥梁。典型例子是专门的提取、转换、加载 (ETL) 工具,它们会将远程数据推送到目标端系统。在基于拉取的模型中,数据库自身连接远程数据源,将数据拉取到本地表中供查询使用,或将数据导出到远程系统。虽然基于推送的方法更灵活、也更常见,但它们往往意味着更大的架构复杂度和可扩展性瓶颈。相比之下,直接在数据库中提供远程连接能力则带来了一些颇具吸引力的能力,例如本地数据与远程数据之间的连接,同时还能保持整体架构简洁并缩短获得洞察的时间。 本节其余部分将介绍 ClickHouse 中用于访问远程位置数据的基于拉取的数据集成方法。需要说明的是,SQL 数据库中的远程连接这一思路并不新鲜。例如,SQL/MED 标准 [35] 于 2001 年提出,PostgreSQL 自 2011 年起实现了该标准 [65],并提出以外部数据包装器作为管理外部数据的统一接口。与其他数据存储和存储格式实现最大限度的互操作性,是 ClickHouse 的设计目标之一。截至 2024 年 3 月,据我们所知,ClickHouse 在所有分析型数据库中提供了最多的内置数据集成选项。 外部连接能力。ClickHouse 提供了 50+ 个集成表函数和引擎,用于连接外部系统和存储位置,包括 ODBC、MySQL、PostgreSQL、SQLite、Kafka、Hive、MongoDB、Redis、S3/GCP/Azure 对象存储以及各种数据湖。我们进一步将它们划分为下方附加图中所示的类别 (不属于原始 vldb 论文内容) 。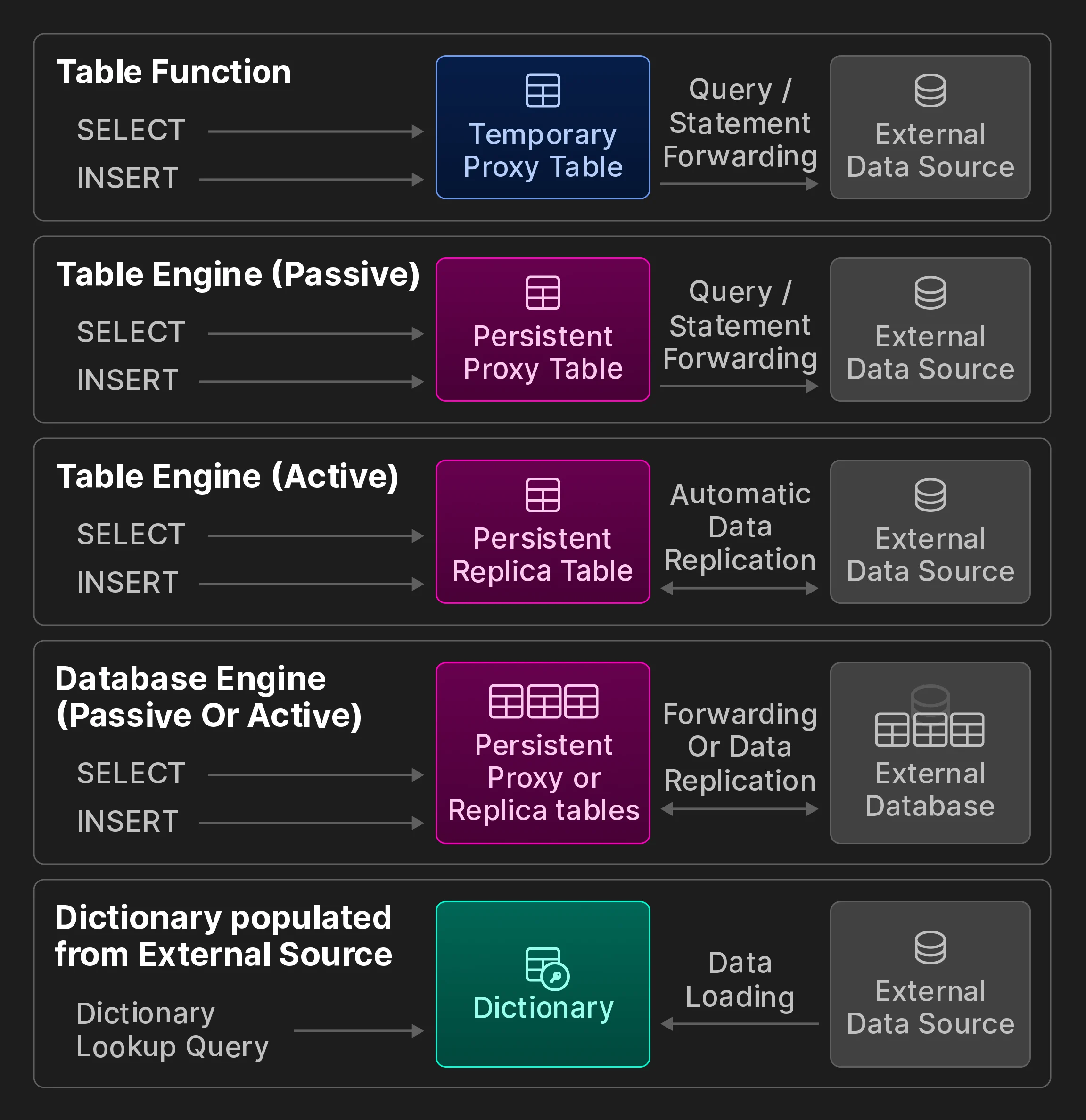
6 性能即特性
6.1 内置性能分析工具
6.2 基准测试
6.2.1 反规范化表
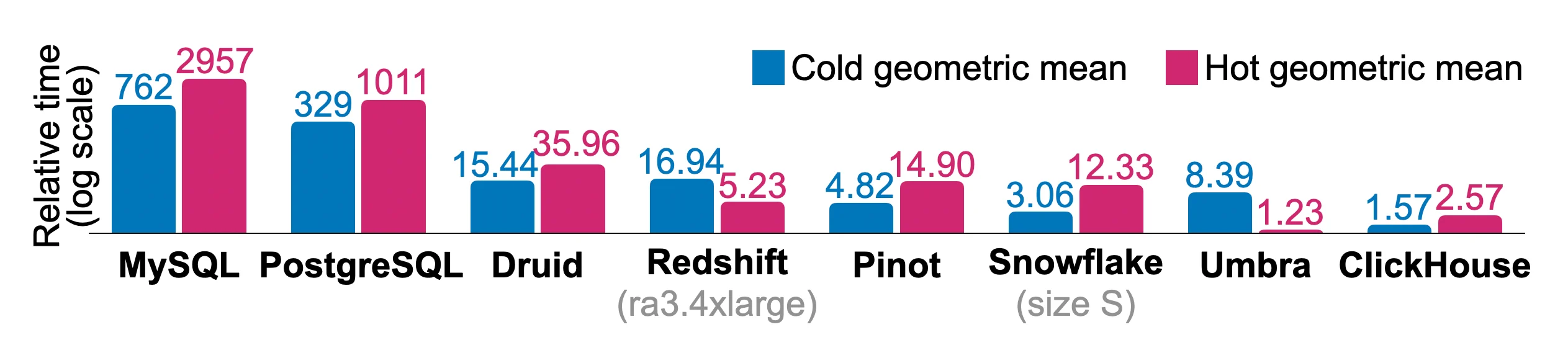
6.2.2 归一化表

8 结论与展望
致谢
参考
- 1 Daniel Abadi、Peter Boncz、Stavros Harizopoulos、Stratos Idreaos 和 Samuel Madden。2013。《现代列式数据库系统的设计与实现》。https://doi.org/10.1561/9781601987556
- 2 Daniel Abadi、Samuel Madden 和 Miguel Ferreira。2006。《Integrating Compression and Execution in Column-Oriented Database Systems》。载于《Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘06)》。671–682。https://doi.org/10.1145/1142473.1142548
- 3 Anastassia Ailamaki、David J. DeWitt、Mark D. Hill 和 Marios Skounakis. 2001. Weaving Relations for Cache Performance. 载于第 27 届超大型数据库国际会议论文集 (VLDB ‘01) . Morgan Kaufmann Publishers Inc.,美国加利福尼亚州旧金山,169–180.
- 4 Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian, and Doug Terry. 2022. Amazon Redshift Re-Invented. 收录于 Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- 5 Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin, and Matei Zaharia. 2022. Photon: A Fast Query Engine for Lakehouse Systems (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- 6 Philip A. Bernstein 与 Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- 7 Spyros Blanas、Yinan Li 和 Jignesh M. Patel. 2011. Design and evaluation of main memory hash join algorithms for multi-core CPUs. 载于 Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD ‘11). Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- 8 Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- 9 Burton H. Bloom. 1970. Space/Time Trade-Ofs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- 10 Peter Boncz、Thomas Neumann 和 Orri Erling。2014。TPC-H Analyzed: Hidden Messages and Lessons Learned from an Infuential Benchmark。收录于 Performance Characterization and Benchmarking。61–76。 https://doi.org/10.1007/978-3-319- 04936-6_5
- 11 Peter Boncz、Marcin Zukowski 和 Niels Nes。2005。MonetDB/X100: Hyper-Pipelining Query Execution。载于 CIDR。
- 12 Martin Burtscher and Paruj Ratanaworabhan. 2007. 双精度浮点数据的高吞吐量压缩。载于 Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- 13 Jef Carpenter 与 Eben Hewitt。2016。Cassandra: The Defnitive Guide (第 2 版) 。O’Reilly Media, Inc.
- 14 Bernadette Charron-Bost、Fernando Pedone 和 André Schiper (编) . 2010. Replication: Theory and Practice. Springer-Verlag.
- 15 chDB. 2024. chDB - 一款嵌入式 OLAP SQL 引擎。检索日期:2024-06-20,来源:https://github.com/chdb-io/chdb
- 16 ClickHouse. 2024. ClickBench: a Benchmark For Analytical Databases. 检索日期:2024-06-20,来源:https://github.com/ClickHouse/ClickBench
- 17 ClickHouse. 2024. ClickBench:对比测评。于 2024-06-20 检索自 https://benchmark.clickhouse.com
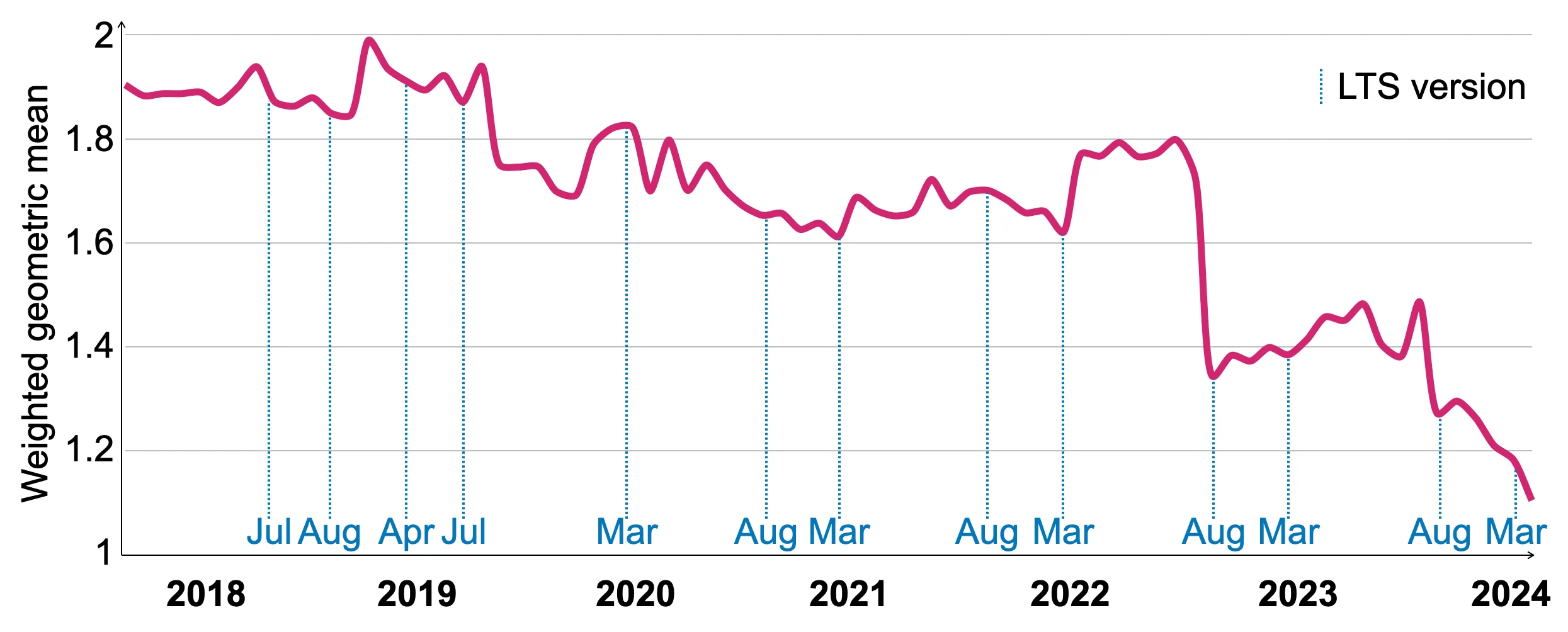
- 18 ClickHouse。2024。ClickHouse 2024 路线图 (GitHub) 。检索于 2024-06-20,来源:https://github.com/ClickHouse/ClickHouse/issues/58392
- 19 ClickHouse. 2024. ClickHouse 版本基准测试。2024-06-20 检索自 https://github.com/ClickHouse/ClickBench/tree/main/versions
- 20 ClickHouse. 2024. ClickHouse 版本基准测试结果。检索于 2024-06-20,来源:https://benchmark.clickhouse.com/versions/
- 21 Andrew Crotty. 2022. MgBench. 2024-06-20 检索自 https://github.com/ andrewcrotty/mgbench
- 22 Benoit Dageville、Thierry Cruanes、Marcin Zukowski、Vadim Antonov、Artin Avanes、Jon Bock、Jonathan Claybaugh、Daniel Engovatov、Martin Hentschel、Jiansheng Huang、Allison W. Lee、Ashish Motivala、Abdul Q. Munir、Steven Pelley、Peter Povinec、Greg Rahn、Spyridon Triantafyllis 和 Philipp Unterbrunner。2016。The Snowfake Elastic Data Warehouse。见 Proceedings of the 2016 International Conference on Management of Data (美国加利福尼亚州旧金山) (SIGMOD ‘16) 。Association for Computing Machinery,New York, NY, USA,215–226。https: //doi.org/10.1145/2882903.2903741
- 23 Patrick Damme、Annett Ungethüm、Juliana Hildebrandt、Dirk Habich 和 Wolfgang Lehner. 2019. From a Comprehensive Experimental Survey to a Cost-Based Selection Strategy for Lightweight Integer Compression Algorithms. ACM Trans. Database Syst. 44, 3,第 9 篇文章 (2019) ,46 页。https://doi.org/10.1145/3323991
- 24 Philippe Dobbelaere 和 Kyumars Sheykh Esmaili. 2017. Kafka 与 RabbitMQ:两种业界参考发布/订阅实现的比较研究:产业论文 (DEBS ‘17) 。Association for Computing Machinery,New York, NY, USA,227–238。https://doi.org/10.1145/3093742.3093908
- 25 LLVM 文档。2024。LLVM 中的自动向量化。检索日期:2024-06-20。来源:https://llvm.org/docs/Vectorizers.html
- 26 Siying Dong、Andrew Kryczka、Yanqin Jin 和 Michael Stumm. 2021. RocksDB:面向大规模应用的键值存储中开发重点的演变。ACM Transactions on Storage 17, 4, 第 26 篇文章 (2021 年) ,32 页。https://doi.org/10.1145/3483840
- 27 Markus Dreseler、Martin Boissier、Tilmann Rabl 和 Matthias Ufacker。2020。TPC-H 瓶颈及其优化的量化分析。Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- 28 Ted Dunning. 2021. The t-digest:分布的高效估计。Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- 29 Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, and Hasso Plattner. 2016. SAP HANA 中利用哈希索引缩减存储占用并强制保证唯一性。载于《Database and Expert Systems Applications》。137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- 30 Philippe Flajolet、Eric Fusy、Olivier Gandouet 和 Frederic Meunier。2007。HyperLogLog:一种近乎最优的基数估计算法分析。载于《AofA: Analysis of Algorithms》,DMTCS Proceedings 第 AH 卷,2007 Conference on Analysis of Algorithms (AofA 07)。Discrete Mathematics and Theoretical Computer Science,137–156。https://doi.org/10.46298/dmtcs.3545
- 31 Hector Garcia-Molina、Jefrey D. Ullman 和 Jennifer Widom。2009。《Database Systems - The Complete Book》 (第 2 版) 。
- 32 Pawan Goyal、Harrick M. Vin 和 Haichen Chen。1996。Start-time fair queueing: a scheduling algorithm for integrated services packet switching networks. 26, 4 (1996) ,157–168。https://doi.org/10.1145/248157.248171
- 33 Goetz Graefe. 1993. Query Evaluation Techniques for Large Databases. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- 34 Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, and Ravi Aringunram. 2018. Pinot: 面向 5.3 亿用户的实时 OLAP。载于 2018 年数据管理国际会议论文集 (美国得克萨斯州休斯敦) (SIGMOD ‘18) 。Association for Computing Machinery, New York, NY, USA, 583–594. https://doi.org/10.1145/3183713.3190661
- 35 ISO/IEC 9075-9:2001 2001。信息技术 — 数据库语言 — SQL — 第 9 部分:外部数据管理 (SQL/MED) 。标准。国际标准化组织。
- 36 Paras Jain、Peter Kraft、Conor Power、Tathagata Das、Ion Stoica 和 Matei Zaharia。2023。湖仓存储系统分析与比较。CIDR。
- 37 Project Jupyter. 2024. Jupyter Notebooks. 于 2024-06-20 检索自 https: //jupyter.org/
- 38 Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. 2018. Everything You Always Wanted to Know about Compiled and Vectorized Queries but Were Afraid to Ask. Proc. VLDB Endow. 11, 13 (sep 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- 39 Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, and Pradeep Dubey. 2010. FAST: fast architecture sensitive tree search on modern CPUs and GPUs. 收录于 Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD ‘10). Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- 40 Donald E. Knuth. 1973. 《计算机程序设计艺术》,第三卷:排序与查找。Addison-Wesley。
- 41 André Kohn、Viktor Leis 和 Thomas Neumann. 2018. Adaptive Execution of Compiled Queries. 见 2018 IEEE 34th International Conference on Data Engineering (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- 42 Andrew Lamb、Matt Fuller、Ramakrishna Varadarajan、Nga Tran、Ben Vandiver、Lyric Doshi 和 Chuck Bear。2012。《Vertica 分析型数据库:C-Store 七年之后》。Proc. VLDB Endow. 5, 12 (2012 年 8 月) ,1790–1801。https://doi.org/10. 14778/2367502.2367518
- 43 Harald Lang、Tobias Mühlbauer、Florian Funke、Peter A. Boncz、Thomas Neumann 和 Alfons Kemper. 2016. Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation. 载于 Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- 44 Viktor Leis、Peter Boncz、Alfons Kemper 和 Thomas Neumann。2014。Morseldriven parallelism: a NUMA-aware query evaluation framework for the manycore age。载于 Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (美国犹他州斯诺伯德) (SIGMOD ‘14) 。Association for Computing Machinery,New York, NY, USA,743–754。https://doi.org/10.1145/2588555. 2610507
- 45 Viktor Leis、Alfons Kemper 和 Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. 收录于 2013 IEEE 第 29 届 International Conference on Data Engineering (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- 46 Chunwei Liu、Anna Pavlenko、Matteo Interlandi 和 Brandon Haynes. 2023. 深入解析分析型数据库管理系统中常见的开放格式。16, 11 (2023年7月) ,3044–3056. https://doi.org/10.14778/3611479.3611507
- 47 Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, and Venkatesh Raghavan. 2021. Greenplum:一种面向事务和分析工作负载的混合数据库 (SIGMOD ‘21) 。美国计算机协会,美国纽约州纽约市,2530–2542。https: //doi.org/10.1145/3448016.3457562
- 48 Roger MacNicol 和 Blaine French。2004。Sybase IQ Multiplex - Designed for Analytics。见 Proceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30 (Toronto, Canada) (VLDB ‘04)。VLDB Endowment,1227–1230。
- 49 Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, and Jef Shute. 2020. Dremel: A Decade of Interactive SQL Analysis at Web Scale. Proc. VLDB Endow. 13, 12 (aug 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- 50 Microsoft. 2024. Kusto 查询语言。2024-06-20 检索自 https: //github.com/microsoft/Kusto-Query-Language
- 51 Guido Moerkotte. 1998. Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing. 收录于第 24 届超大型数据库国际会议论文集 (VLDB ‘98) . 476–487.
- 52 Jalal Mostafa、Sara Wehbi、Suren Chilingaryan 和 Andreas Kopmann。2022。SciTS:A Benchmark for Time-Series Databases in Scientifc Experiments and Industrial Internet of Things。见 Proceedings of the 34th International Conference on Scientifc and Statistical Database Management (SSDBM ‘22)。Article 12。https: //doi.org/10.1145/3538712.3538723
- 53 Thomas Neumann. 2011. efficiently Compiling efficient Query Plans for Modern Hardware. Proc. VLDB Endow. 4, 9 (2011年6月) , 539–550. https://doi.org/10.14778/ 2002938.2002940
- 54 Thomas Neumann 和 Michael J. Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. 见第 10 届创新数据系统研究大会 (CIDR 2020) ,荷兰阿姆斯特丹,2020 年 1 月 12–15 日,在线论文集。 www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- 55 Thomas Neumann、Tobias Mühlbauer 和 Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. 载于 Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD ‘15). Association for Computing Machinery, New York, NY, USA, 677–689. https://doi.org/10.1145/2723372. 2749436
- 56 GitHub 上的 LevelDB。2024。LevelDB。检索自 2024-06-20:https://github. com/google/leveldb
- 57 Patrick O’Neil、Elizabeth O’Neil、Xuedong Chen 和 Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. 收录于 Performance Evaluation and Benchmarking. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- 58 Patrick E. O’Neil、Edward Y. C. Cheng、Dieter Gawlick 和 Elizabeth J. O’Neil。1996。《The log-structured Merge-Tree (LSM-tree)》。Acta Informatica 33 (1996):351–385。https://doi.org/10.1007/s002360050048
- 59 Diego Ongaro 与 John Ousterhout. 2014. In Search of an Understandable Consensus Algorithm. 发表于 Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference (USENIX ATC’14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- 60 Patrick O’Neil、Edward Cheng、Dieter Gawlick 和 Elizabeth O’Neil。1996。The Log-Structured Merge-Tree (LSM-Tree)。Acta Inf. 33, 4 (1996), 351–385。https: //doi.org/10.1007/s002360050048
- 61 Pandas。2024。《Pandas 数据框》。检索于 2024-06-20,来源:https://pandas. pydata.org/
- 62 Pedro Pedreira、Orri Erling、Masha Basmanova、Kevin Wilfong、Laith Sakka、Krishna Pai、Wei He 和 Biswapesh Chattopadhyay. 2022. Velox:Meta 的统一执行引擎。Proc. VLDB Endow. 15, 12 (2022 年 8 月), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- 63 Tuomas Pelkonen、Scott Franklin、Justin Teller、Paul Cavallaro、Qi Huang、Justin Meza 和 Kaushik Veeraraghavan. 2015. Gorilla:一种快速、可扩展的内存时序数据库。《VLDB Endowment 论文集》8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- 64 Orestis Polychroniou、Arun Raghavan 和 Kenneth A. Ross. 2015. 重新思考内存数据库的 SIMD 向量化。载于 2015 ACM SIGMOD 数据管理国际会议论文集 (SIGMOD ‘15) 。1493–1508. https://doi.org/10.1145/2723372.2747645
- 65 PostgreSQL. 2024. PostgreSQL - 外部数据包装器。2024-06-20 检索自 https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- 66 Mark Raasveldt、Pedro Holanda、Tim Gubner 和 Hannes Mühleisen. 2018. 公平基准测试并非易事:数据库性能测试中的常见陷阱。见《数据库系统测试研讨会论文集》 (Houston, TX, USA) (DBTest’18). 文章 2,6 页。https://doi.org/10.1145/3209950.3209955
- 67 Mark Raasveldt 和 Hannes Mühleisen. 2019. DuckDB:一种可嵌入式分析型数据库 (SIGMOD ‘19) . 美国纽约州纽约市:计算机协会,1981–1984. https://doi.org/10.1145/3299869.3320212
- 68 Jun Rao and Kenneth A. Ross. 1999. Cache Conscious Indexing for Decision-Support in Main Memory. 见 Proceedings of the 25th International Conference on Very Large Data Bases (VLDB ‘99). 美国加利福尼亚州旧金山,78–89.
- 69 Navin C. Sabharwal and Piyush Kant Pandey. 2020. 使用 Prometheus 查询语言 (PromQL) 。见 Monitoring Microservices and Containerized Applications. https://doi.org/10.1007/978-1-4842-6216-0_5
- 70 Todd W. Schneider. 2022. 纽约市出租车和受雇车辆数据。检索日期:2024-06-20,来源:https://github.com/toddwschneider/nyc-taxi-data
- 71 Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. 2005. C-Store: A Column-Oriented DBMS. 载于第 31 届超大型数据库国际会议论文集 (VLDB ‘05) 。553–564.
- 72 Teradata. 2024. Teradata Database. 于 2024-06-20 检索自 https://www. teradata.com/resources/datasheets/teradata-database
- 73 Frederik Transier. 2010. Algorithms and Data Structures for In-Memory Text Search Engines. 博士论文。 https://doi.org/10.5445/IR/1000015824
- 74 Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, and Manuel Then. 2018. 直面现实:基准测试为何无法反映真实世界。载于 Proceedings of the Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18) 论文集。文章 1,6 页。https://doi.org/10.1145/3209950.3209952
- 75 LZ4 网站。2024。LZ4。于 2024-06-20 检索自 https://lz4.org/
- 76 PRQL 网站。2024。PRQL。访问日期:2024-06-20,https://prql-lang.org 77 Till Westmann、Donald Kossmann、Sven Helmer 和 Guido Moerkotte。2000。《压缩数据库的实现与性能》。SIGMOD Rec.
- 29, 3 (2000 年 9 月) , 55–67. https://doi.org/10.1145/362084.362137 78 Fangjin Yang、Eric Tschetter、Xavier Léauté、Nelson Ray、Gian Merlino 和 Deep Ganguli. 2014. Druid: A Real-Time Analytical Data Store. 见 Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14) . Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- 79 Tianqi Zheng, Zhibin Zhang, 和 Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- 80 Jingren Zhou 和 Kenneth A. Ross. 2002. Implementing Database Operations Using SIMD Instructions. 见 Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘02). 145–156. https://doi.org/10. 1145/564691.564709
- 81 Marcin Zukowski、Sandor Heman、Niels Nes 和 Peter Boncz。2006。Super-Scalar RAM-CPU Cache Compression。In Proceedings of the 22nd International Conference on Data Engineering (ICDE ‘06)。59。https://doi.org/10.1109/ICDE. 2006.150